For the past several years, a growing body of research—including several CSET publications—has warned that malicious actors could use large language models (LLMs) to generate content to deploy in influence operations, supplementing or even fully replacing much of the human labor that currently underwrites these campaigns. Consensus has emerged that LLMs can be as convincing as human-authored propaganda in at least some contexts, and the capabilities of cutting-edge models continue to improve.
At the same time, even if LLMs can write convincing content, it is not obvious that all propagandists will have strong economic incentives to deploy them at scale. After all, training LLMs from scratch can be extremely expensive, and user-friendly models like ChatGPT (or at least the most capable versions of it) aren’t free to use. Some reporting also suggests that existing influence operations are already extremely cheap, which has led some AI researchers to suggest that the threat of propagandists using LLMs to produce disinformation is overhyped—or that it wouldn’t even save money.
Understanding whether or under what conditions propagandists will have an economic incentive to use LLMs for content generation is difficult, given the opacity of influence operations. But one way to narrow the uncertainty is to use publicly available information about influence operations and a mathematical modeling approach to attempt to evaluate the question. In a paper uploaded yesterday to the preprint server arXiv, I attempt to do just that. In this companion blog post, I provide a nontechnical overview of the work and its implications for policymakers.
Model Setup
The method used in this research assumes that a propagandist needs to author a large number of discrete bits of content (call them “tweets”) to post online. There are three basic ways that they can choose to do this:
- They might simply choose to pay humans to write the content for them. (Call this scenario the “manual campaign.”)
- They might instead sign up to use an LLM like ChatGPT. In this scenario, humans are still responsible for writing prompts which are submitted to the model and processed by a third party entity which owns the model, and humans must also review the outputs to decide whether or not they are sufficiently high-quality to post. However, because the model itself is controlled by a third party, that party can monitor the types of prompts they submit and cut off their access to the model if they appear to be using it maliciously. (Call this scenario the “third party model.”)
- The propagandist can instead choose to create their own model, either by training it from scratch, or by downloading an existing open source model and fine-tuning it for their purposes. In this scenario, the propagandist must pay an upfront cost to get access to the model, and someone must still do the work of prompting the model and reviewing its outputs, but there is no longer a risk that the propagandist may lose access to the model because someone detects their efforts to misuse it. (Call this scenario the “internal model.”)
To calculate the relative cost of each of these three strategies, I make use of the following parameters:
- w: the hourly wage that a propagandist pays to their employees, whether those employees are writing content from scratch or reviewing outputs from an LLM.
- L: the productivity of human authors when writing content from scratch, measured as tweets per hour.
- ɑ: a speedup factor that represents how much faster humans can review outputs from an LLM, compared to writing them from scratch.
- IC: the inference costs of an LLM (that is, the price of actually running a model or paying a third party to run a model to generate one output).
- p: the performance of the model on the given task, measured as the percent (0.0 to 1.0) of its outputs that are sufficiently high-quality for the propagandist to use.
- λ: the ability of the third party to detect misuse of their model, measured as probability of detection per output.
- P: the penalty that the propagandist pays if their misuse is detected (for instance, the cost of extra labor time used to evade a ban with new accounts).
- FC: the fixed costs that a propagandist must pay to get a model of their own running, including training or fine-tuning costs, if they choose to do so.
Using these parameters, we can write a few equations that describe how costly it would be to generate n unique outputs for posting online under each of the three scenarios above. For a manual campaign, this cost is:

For a campaign using a third party model with monitoring controls in place, this cost is:
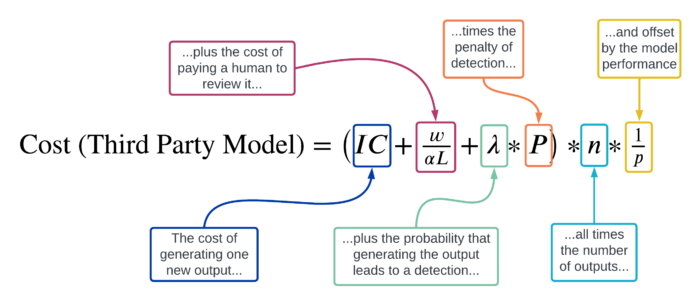
And finally, for a campaign that expends a fixed cost in order to acquire and use a model internally, the cost is:
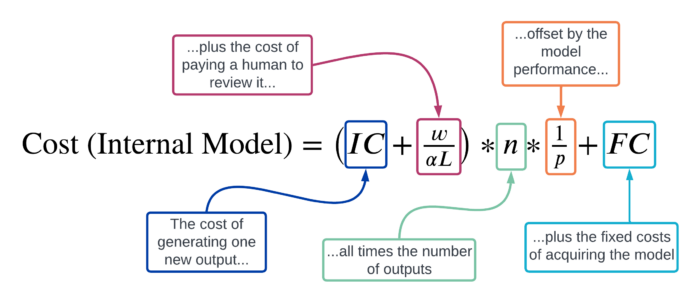
Once values for all of these parameters have been chosen, it is easy to calculate the expected costs under each scenario and determine which approach might be most cost effective for a propagandist. In addition, if all parameters but one can be estimated, it is possible to solve for some values of interest. For instance, what level of monitoring capability is necessary to deter a malicious actor from using a privately owned GPT-like model under various scenarios? Or, given a necessary fixed cost expenditure to acquire a model with a given capability, how many posts must a propagandist expect to use the model for before it would be cost effective to pay the upfront investment?
Estimating the Parameters
Some of the parameters above are very difficult to estimate. For instance, the performance of a given model on a given task will vary widely across both models and applications. However, other parameters can be loosely estimated using publicly available information. For instance, through job postings and investigative reporting, we know a little bit about the wages that are paid to low-level propaganda authors in the Russian Internet Research Agency (IRA), as well as a little bit about the quotas for content authorship they are expected to meet—information which corresponds to w and L in the above equations. In addition, recent analyses of programmers working alongside code-completion AI models like GitHub Copilot offer insight into ɑ, the relative speedup between reviewing an AI’s outputs versus writing them yourself.
In the accompanying arXiv preprint, I offer plausible ranges for w, L, IC, ɑ, and P. But these plausible ranges can be large, making it hard to be confident in conclusions derived from any one choice of parameter values. To address this uncertainty, the calculations rely upon a method called Monte Carlo estimation: for each variable, I randomly choose a value from within its plausible range and calculate what the result would be based on those input values. By doing this repeatedly, we can examine how sensitive the result is to changes in the input values, which input values most heavily impact the result, and how confident we can be in the final estimated result. This can be useful to identify the right interventions. For instance, if it turns out that small changes to the parameter λ cause large changes in how much propagandists can expect to save when using LLMs, then this tells us that investing in better detection capabilities could have a large deterrent effect on malicious use of LLMs. Alternatively, if the economic usefulness of LLMs depends most heavily on p, then reducing a model’s performance (say, by training it to not comply with user requests that appear to be malicious) may be a better intervention.
Overview of Results
One initial finding of this work is that LLMs do not have to be highly reliable in order for their use to be cost effective. Given the ranges for w, L, IC, and ɑ described in the accompanying arXiv preprint, we can estimate that LLMs only need to produce usable outputs for a given propaganda task roughly 25% of the time for them to be as cheap as human authorship.1 Figure 1 below shows the distribution of per-output savings and estimated break-even performance values as we vary the input parameters across their plausible ranges; in almost all cases, by the time an LLM is 50% reliable or better at producing usable outputs, it is cheaper to use the LLM than to rely on only manual authorship. Considering that existing models like ChatGPT reliably fool humans into believing that their content is human-authored, it seems fair to conclude that existing LLMs could offer large savings to propagandists.
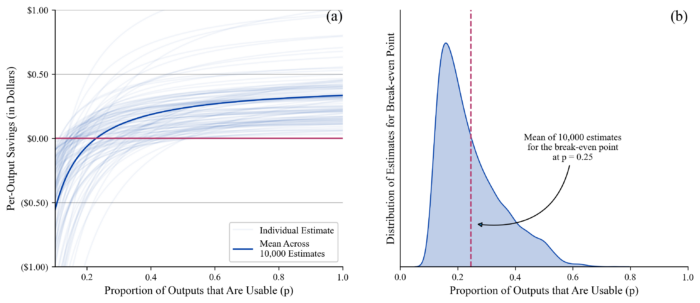
Note: Figure 1(a): As LLMs become more reliable, estimated savings per output rise quickly before leveling off, though there is large variation across estimates. Figure 1(b): Across all 10,000 estimations, LLMs become cost effective to use at around 25% reliability on average.
Over the course of a ten-million-tweet campaign, for instance, savings from a model that was reliable 75% of the time would be expected to top $3 million. However, the calculations also suggest that detection capabilities could still impose sufficient costs to deter malicious use. For instance, the $3 million in savings could potentially be entirely wiped out if the propagandist had a 10% chance of being detected with each output they generated, and if each successful detection cost them (on average) about an hour of extra worker time to evade.2 While this level of detection capability would be extremely hard to achieve in practice, even less reliable detection capabilities could impose meaningful costs.
The calculations can also be used to analyze how propagandists could choose between the use of third party LLMs and open source ones that can be downloaded and run internally. Figure 2 shows which type of model the propagandist may use based upon their relative performance capabilities.3 If neither model is good at all (the lower left-hand corner of the figure), then the propagandist is still better off relying on human authorship. If the public, open source model performs better than the third party one (the top left-hand portion of the figure), then the propagandist will prefer to use the open source one, and monitoring controls on the third party model will have no deterrent impact. By contrast, if the private, third party model is better than the public, open source model (the right and lower portions of the figure), then the propagandist would prefer to use the third party model—but can be deterred from doing so by monitoring controls if they can impose meaningful costs. The green hues in the figure show the minimum detection capability that would be necessary to cause the propagandist to give up on using the private, third party model.
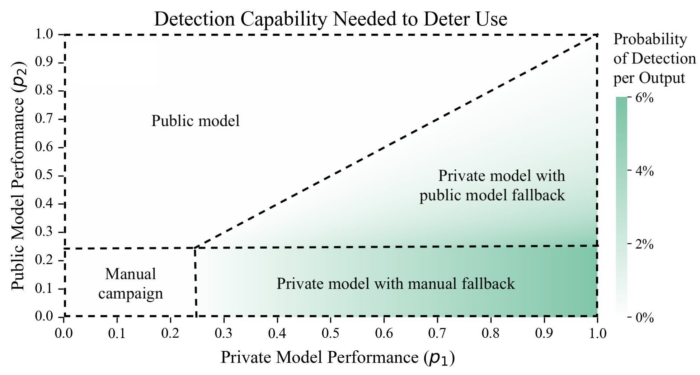
Note: Figure 2. Regions of the figure correspond to the propagandist’s preferred model choice for various combinations of public, open source and private, third party LLM capabilities. Green shading indicates the detection reliability on the third party model necessary to deter the propagandist from using it.
Note that right now, there are many highly-capable open source models available, but the best-performing models are mostly held by private entities that allow customers limited (and monitorable) access to the models. In other words, the real world situation for many tasks probably corresponds to some area on the above figure a little bit below the diagonal line. This suggests that propagandists should be expected to try to use third party models like ChatGPT to produce content. But monitoring capabilities that cut off access to the model with roughly a 1% probability per output may be sufficient to cause propagandists to switch to instead using open source models that can be fine-tuned and run internally.
Finally, the calculations can be extended to evaluate under what circumstances propagandists should be willing to pay large upfront costs to train or fine-tune custom models. For instance, if a propagandist could quickly download and fine-tune an open source model that was 85% reliable, but could only reach 100% reliability by training a ChatGPT-sized model from scratch, would it ever be worth paying the larger cost to train a model from scratch? This research, at least, suggests not, unless the propagandist was operating at scales substantially larger than existing nation-state influence operations.
Conclusions
It is difficult to evaluate the exact impact that LLMs will have on future influence operations. But it is not impossible to make some estimates with the aid of publicly available reporting and mathematical modeling. Doing so is useful if it (1) adds more precision to the conversation and reduces speculation and (2) helps analysts to better evaluate and compare the impact of various intervention strategies. This work, more fully described in the accompanying arXiv preprint, attempts to do just that.
Although there is still much uncertainty around this work, some general conclusions are clear enough. First, it is all but certain that a well-run human-machine team that utilized existing LLMs would save a propagandist money on content generation. Second, it is clear that under many scenarios, propagandists—even nation-state actors—may not have economic incentives to use the most cutting-edge LLMs in their operations. For instance, a decently performing model that can be fine-tuned cheaply will almost always be more cost effective than a much larger model that requires training from scratch in order to reach better levels of reliability. And in some cases, especially for relatively small or decentralized campaigns, propagandists may choose to use third party models, even when they are fully aware that this means their activity is being monitored.
This work is a preliminary attempt to explore these issues. Hopefully, it can inspire further refinements from others, while also helping to reduce speculation that often accompanies discussions of LLMs and disinformation. It is also intended to help point—even if only generally—towards an understanding of the particular drivers of LLMs’ value for propagandists, which in turn may allow for more informed decisions regarding how to disrupt that value. But actually doing so will remain a difficult challenge, both for the AI and policy communities.
- This particular estimate assumes that no monitoring controls are in place on a third party model, or (under the internal model scenario) that the fixed costs of acquiring a model are $0.
- Note that detection of misuse of a model is distinct from the detection of malicious content posted to platforms themselves. Both content from LLMs and human authors can be detected on social media, though it may actually be harder to detect LLM-generated content than human-generated content if the latter makes heavy use of repetitive content (“copypasta”) and the former does not. Detecting content that has already been posted online, however, doesn’t affect the costs of generating the content in the first place, while the ability to detect (and restrict access to) malicious use of a third party model does.
- This figure is based on the assumption that there are no upfront costs to acquiring the internal model; the higher those fixed costs actually are, the larger the propagandist’s incentive would be to continue relying on a third party model even if their misuse is frequently detected.