This is the first installment of a three-part blog series. To read the second part, click here. And to read the third part, click here.

In this explainer:
- How LLMs learn to predict the next word.
- Why and how LLMs turn words into numbers.
- Why learning to predict the next word is surprisingly powerful.
Large language models (LLMs) are best known as the technology that underlies chatbots such as OpenAI’s ChatGPT or Google’s Gemini. At a basic level, LLMs work by receiving an input or prompt, calculating what is most likely to come next, and then producing an output or completion. The full story of how LLMs work is more complex than this description, but the process by which they learn to predict the next word—known as pre-training—is a good place to start.
If you are given the sentence, “Mary had a little,” and asked what comes next, you’ll very likely suggest “lamb.” A language model does the same: it reads text and predicts what word is most likely to follow it.1
The right input sentence can turn a next-word-prediction machine into a question-answering machine. Take this prompt, for example:
“The actress that played Rose in the 1997 film Titanic is named…”
When an LLM receives a sentence like this as an input, it must then predict what word comes next. To do this, the model generates probabilities for possible next words, based on patterns it has discerned in the data it was trained on, and then one of the highest probability words is picked to continue the text.2 Here’s a screenshot from an OpenAI model, showing the words it estimated to be most probable continuations in this case (highlighted text was generated by the model):
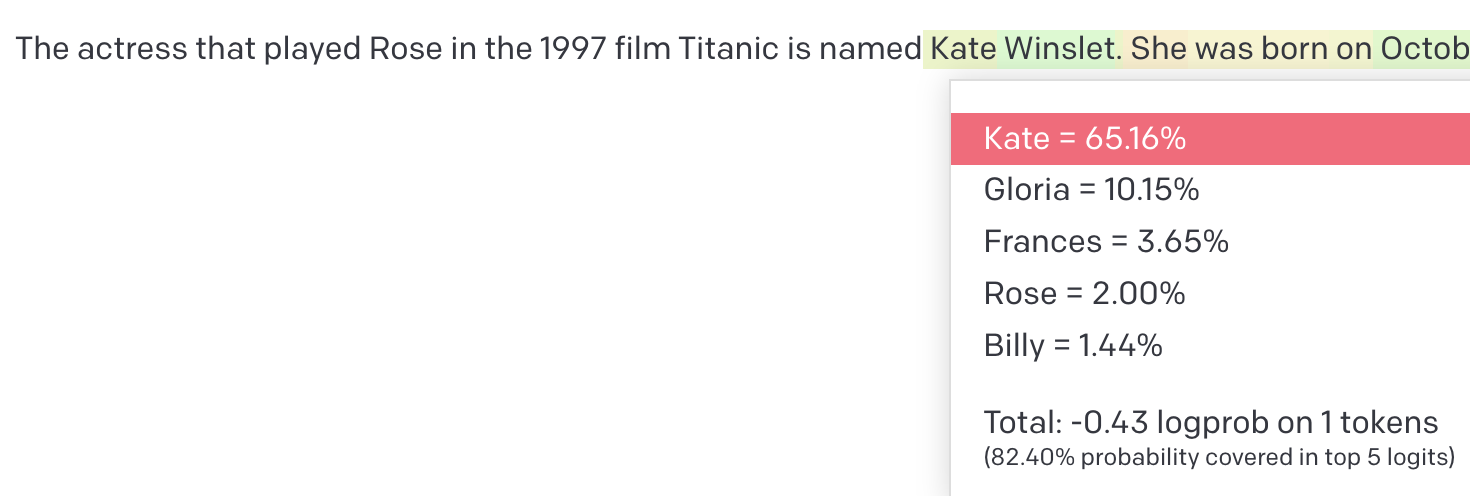
Source: Author experimentation with text-davinci-003.
In this case, correctly predicting the next word meant that the model provided the user with a fact—and by doing so, answered the user’s implicit question in the input. Let’s look at one more example that goes a step further, using next-word prediction to carry out a simple task. Consider the following prompt:
“Now I will write a Python function to convert Celsius to Fahrenheit.”
Like the previous example, the model takes this input text and predicts what words come next—in this case, functioning code to carry out the task in question, as shown in this screenshot:

Source: Author experimentation with text-davinci-003.
In some sense, this input “tricks” the LLM into outputting a Python function by asking the model to complete the text. It’s as if the LLM were an improv partner and was continuing the scene by writing the correct code. This approach demonstrates how a next-word-prediction machine can not only answer questions but also carry out useful tasks.
These examples only involve short chunks of text, but the same principle can be used to generate longer texts, too. Once the model has predicted one word, it simply keeps predicting what will come next after the text it has already produced. It can carry on in this fashion indefinitely, though the generated text will generally become less coherent as it gets more distant from the initial input.
Explanations of how LLMs work often stop there: with predicting the next word. But as mentioned above, predicting the next word isn’t the whole story of how ChatGPT and similar systems do what they do. Learning to predict the next word happens in a step called pre-training, and it’s only one of several key steps in the development process of today’s LLMs. Subsequent posts in this series dive into the limitations of next-word prediction, and what other techniques AI developers use to build LLMs that work well. But first, the rest of this post explains more about how pre-training works—and why it has been so pivotal in creating AI systems that appear to have something resembling an understanding of the world.
Self-Supervised Pre-training: How LLMs Learn to Predict the Next Word
LLMs learn to predict the next word by recognizing patterns in enormous quantities of text data, a process called self-supervised pre-training. Today’s LLMs use data drawn from sources across the internet, such as Wikipedia, books, and internet forum discussions. Unlike supervised learning, where the data is annotated by humans, the next word predicted by a self-supervised model is checked against the actual next word in the raw data.
Let’s consider how an LLM would learn from an example like “Mary had a little lamb” during training:
- The LLM looks at only the first word—“Mary”—and makes a guess at how likely it is that different words might come next.
- The LLM’s prediction is compared with the actual next word as it appears in the data.3
- The LLM is updated to make correct predictions more likely. A mathematical process called “backpropagation” adjusts the numbers inside the model—called parameters— so that they are more likely to predict the correct next word, ”had.”
- Now the model looks at the first two words in the original text—”Mary had”—and tries to predict the third. The process returns to step #2 and continues from there.
In this way, LLMs are developed using a process that could roughly be described as guessing, checking, and updating. This process is what the word “learning” refers to in the phrase “machine learning.”
An important component of how this process works is how the model learns to represent words as numbers. Like all machine learning models, LLMs work by adding and multiplying numbers together, so they can’t process words directly. Instead, words are chunked into parts, called tokens. Then, these tokens are transformed into a long list of numbers. This long list of numbers is called a word embedding. Word embeddings play a crucial role in how an LLM captures the meaning of language. At first, they start as random numbers. However, throughout the training process (guess, check, and update), the language model learns how different words relate to each other, based on patterns in the massive text datasets that are used for training. What makes word embeddings interesting—and useful—is that the numbers for any given word can be treated as coordinates, which represent each word as a point in space that can be compared to the locations of other words. Words whose embeddings are closer to each other tend to have more similar meanings. For example, the embedding for “raccoon” would be closer to the embedding for “rabbit” than that for “table” or “justice.” What’s more, the spatial relationships between words can also represent meaningful ideas. For example, the distance and direction between “Italy” and “Rome” might be similar to the distance and direction between “France” and “Paris.”
For interested readers, there are many resources available online that go into more depth on how LLMs predict the next word. This interactive Financial Times article gives an accessible, broad-strokes explanation of word embeddings and of the transformer, a type of neural network that has powered the recent advances in LLMs. This blog post is a more in-depth and technically accurate—though still introductory—resource.
Self-supervised pre-training is now the standard place to start when developing AI systems that work with language, and is increasingly common in other areas of AI, too. To understand why pre-training has become so popular—and why it’s called “pre-training” in the first place—we need to briefly look back in time.
What Do You Need to Predict the Next Word? Representations and Transfer Learning
For many years, the typical approach in machine learning has been to train a model for one specific task using a dataset tailored to that task. For example, a model for detecting tumors in X-rays would be trained on a dataset of X-ray images with and without tumors, while a self-driving car would be trained on data showing situations the car might encounter on the road.
In contrast, the idea behind pre-training is to first train the model to perform a more generic task on a broader dataset and then refine the pre-trained model to excel at the task of interest, rather than starting from scratch. Discovering how well this approach works across a range of domains has been one of the most important trends in AI in recent years. In addition to language modeling, pre-training has also turned out to be useful in other domains, including computer vision, speech recognition, and robotics.
A research project that OpenAI published in 2017, more than a year before they created their first GPT (or “generative pre-trained transformer”) model, is an illustrative example of how pre-training works and what makes it interesting. The project focused on “sentiment analysis,” the task of determining whether the mood of a movie review or other piece of text is positive, negative, or neutral. AI researchers who focus on language have spent decades trying to create AI models that can do this task well, typically using datasets consisting of chunks of text that have been hand-labeled by humans. In contrast, OpenAI’s 2017 project created a pre-trained model that was trained only to predict the text of a product review, one character at a time—a much more generic task. Once it was able to achieve good performance, the researchers realized that as a by-product, part of the model was actually also extremely good at sentiment analysis—determining whether a review was positive or negative—despite never being trained specifically for that.
This phenomenon is sometimes known as transfer learning, when a model trained for one task (in this case, predicting the next character of a review) seems to be able to transfer what it learned to a different task (analyzing whether a review was positive or negative). We can infer that figuring out whether a review was favorable or not must have somehow helped the model to predict how the review would continue, so it incidentally learned how to do sentiment analysis on the way to learning next-character prediction.
AI researchers explain transfer learning by saying that the model learned a useful “representation” of text from its training data. While experts disagree fiercely about whether it is appropriate to say machine learning models “understand” things about the world, the idea that models learn statistical representations of data—and that some ways to represent data are more useful than others—is uncontroversial.
Today’s LLMs learn representations that not only let them predict the structure of language (e.g., that “the” is usually followed by a noun), but also much of the content of language (e.g., facts like Kate Winslet’s starring role in Titanic). This allows them to make light work of tasks that were challenging for earlier systems, such as identifying what “it” is referring to in the sentence, “The trophy would not fit in the brown suitcase because it was too big.”4 Most intriguingly of all, large-scale pre-training appears to give models some ability to problem-solve their way through tasks not seen in the training data, though the extent to which this is evidence of true reasoning ability is hotly debated. At a minimum, it is clear that the simple task of learning to predict the next word allows models to develop statistical representations of language that act as a powerful foundation to achieve a range of different tasks.
It may seem surprising that predicting the next word could allow LLMs to complete tasks we often consider to require common sense, knowledge, or reasoning ability. But, considered a different way, it can seem more intuitive: if you were given the task of predicting what would come next in a math textbook or an interview with a historian, you would be more able to do so if you knew (in some sense) some things about math or history. It remains to be seen how sophisticated LLMs can become on the basis of learning to predict the next word. But the repeated lesson of recent years is that the statistical representations models learn in order to predict the next word can be more powerful than one might expect.
Beyond Pre-training
An LLM that has only been pre-trained on next-word prediction (generally referred to as a “base model”) won’t act quite like ChatGPT or other familiar LLMs do. It won’t reliably follow instructions—for instance, if the Python example above were phrased as, “Please write a Python function to convert from Celsius to Fahrenheit,” it likely would not generate a useful answer. What’s more, such a model will produce text that mirrors the internet text it was trained on—hate speech, dangerous information, and all. The next post in this series goes into more detail about the limitations of models that have only been pre-trained, and how AI developers solve those problems.
Thanks to John Bansemer, Di Cooke, Hanna Dohmen, James Dunham, Rachel Freedman, Krystal Jackson, Ben Murphy, Jack Titus, Vikram Venkatram, and Thomas Woodside for their feedback on this post.
- Technically, some language models predict words in the middle of a text, instead of what comes at the end, but next-word prediction is very common.
- Intuitively, it might seem like the LLM should always pick the single highest-probability word, but in practice this can lead to formulaic or repetitive text. AI developers manage this using a setting called temperature, which adjusts the confidence of model predictions. Lower temperature can be more appropriate for use cases where more definitive answers are desirable (e.g., when asking factual questions), while higher temperature can lead to more interesting and varied text.
- In a little more detail: the probability that the model assigns to the correct answer is used to calculate the value of a “loss function,” which is a way of quantifying how incorrect the model’s answers are. The higher the probability the model assigned to the right answer, the lower the loss. This loss function is then used to determine how the model should be updated.
- This question is an example of a “Winograd Schema,” a question in which some amount of common sense and world knowledge is required to disambiguate what a pronoun is referring to.