The National Artificial Intelligence Research Resource (NAIRR) pilot, launched by the National Science Foundation (NSF) and the Office of Science and Technology Policy (OSTP) in January 2024, is an initiative to provide federal infrastructure to U.S. AI researchers. The two-year pilot, which will eventually expand and include additional resources, is a proof of concept that provides selected researchers with computational, data, and training resources for AI discovery and innovation, particularly for research on safe, secure, and trustworthy AI. The objectives are to demonstrate value and impact, support research with participation from broad communities, and gain initial experience in preparation for a full NAIRR implementation.
A key element of the NAIRR pilot is the provision of computational resources, many of which are sourced from pre-existing NSF systems. Such resources are often unavailable to researchers outside of well-resourced organizations. As stated in the NAIRR Task Force’s implementation plan, “this access divide limits the ability to leverage AI . . . [and] constrains the diversity of researchers in the field and the breadth of ideas incorporated into AI innovations.” These resources are intended to help bridge this access divide and support aspects of AI research that may be deprioritized in the private sector.
The purpose of this blog post is to make an initial assessment of the compute contributions to the NAIRR pilot to understand how it bridges the access divide between well-resourced companies and more resource-constrained organizations and academic institutions. We estimate that the total compute capacity of the initial NAIRR pilot resources is roughly 3.77 exaFLOPS, the equivalent of approximately 5,000 H100 GPUs (using the tensor cores optimal for AI). Most resources are not available for year-round use; many are already near capacity and are used for non-AI research, but can be allocated for short-term AI projects through the NAIRR. We calculate the total allocated FLOPs by factoring in the amount of time the resources can be used for AI projects, and find that it is roughly 3.2 yottaFLOPs.
This overall compute is sufficient to train some of the largest foundation models developed to date—however, no single project can or will receive all the computing resources. Therefore, we also provide estimates for the individual commitments from six federal laboratories and advanced computing centers. The largest NAIRR resource, the Summit supercomputer, can support very large-scale AI training, but its utility is limited because it is expected to be decommissioned in October 2024. The second and third largest resources, the Frontera and Delta supercomputers, can also support large-scale training but to a lesser degree. The remaining resources are likely suited for less computationally demanding use cases.
Methodology
To conduct this estimation, we calculate the processing speed of the hardware from each NAIRR resource, which is measured in Floating Point Operation per Second or FLOPS—herein primarily referred to as “compute.” Compute specs are sourced from the NAIRR pilot website, the websites of the systems developers, and TechPowerUp (see Table 1 below for more details). In instances where information from the NAIRR does not reflect information provided by other sources, we defer to the NAIRR. Moreover, hardware specifications across NAIRR resources are not always uniformly reported. They are often reported in different levels of precision (i.e., the number of bits per floating point number), therefore we convert all data to half-precision to allow for direct comparisons (where applicable, we use half-precision tensor core performance without sparsity).
Once compute is calculated, we then pull information from the NAIRR allocations page to determine the amount of time the resources are available for AI projects. Assessing the compute capacity, along with the amount of time that compute is available for use, provides a clearer sense of the compute provisioned through the NAIRR. Lastly, we assessed the initial NAIRR resources as of April 2024, and do not include resources added to the pilot after the writing of this blog post, but the compute of many of the newer NAIRR resources can be calculated using the same methodology. See the CSET Github for details on the calculations.
We also estimate how long it would take to train the following models on the NAIRR hardware, assuming there is sufficient working memory to load them: Gemini Ultra, GPT-4, GPT-3.5, Claude 2, and LLama 2-70B. We use the Epoch AI Database for estimates of the compute and time required to train these models.
NAIRR Pilot Compute
The NAIRR pilot provides access to six high-performance computing (HPC) resources, which we broadly categorize as either “general-purpose” systems that can be used for various scientific applications, or “AI-specific” systems designed for machine learning:
- The general-purpose resources are the Summit, Frontera, and Delta supercomputers, which are currently in the Top500 list of the most powerful commercially available computer systems in the world, as well as the Lonestar6 system. The NAIRR will provision these four resources for AI research, but they are also used for modeling and simulation, data analysis, materials discovery, and other applications.
- The AI-specific resources are the ACLF AI Testbed and Neocortex, which both employ systems optimized for machine learning applications.
These resources provide roughly 3.77 exaFLOPS of compute capacity in total, assuming full utilization of the hardware. This includes approximately 27,500 CPUs, 29,000 GPUs, and six specialized systems designed for AI workloads. For perspective, a straight conversion of this overall compute to GPUs indicates that this is equivalent to roughly 5,000 H100 GPUs (using the tensor cores optimal for AI). This capacity is allocated to AI projects for periods of time. NAIRR AI projects have access to these resources for about 3.3 million GPU or node hours, and the overall compute allocated is roughly 3.2 yottaFLOPs. For perspective, this total compute allocated is likely sufficient to train large language models like GPT-3.5 or Claude 2 once, but not enough to train models like Gemini 1.0 Ultra or GPT-4. Note that 750,000 of these GPU/node hours were not designated for specific systems, and therefore we omit them from our calculations.
Comparing this to the compute available within industry is challenging, as few companies report their GPU purchases. However, some assessments indicate that Meta and Microsoft have each purchased over 150,000 H100s, while Google and Amazon have each purchased 50,000 (in addition to other types of GPUs). Moreover, in a public statement, Meta stated its intent to purchase over 350,000 H100s by the end of 2024. This suggests that overall NAIRR compute, while significant, is not at the scale of major technology companies—a gap that is even more pronounced when compared to individual NAIRR resources.
As displayed in Figure 1, most compute comes from the Summit, Frontera, and Delta supercomputers, which make up about 87.5%, 4.5%, and 4% of the overall compute capacity, respectively. Summit contains over 9,000 CPUs and 27,500 GPUs, making it suited for large-scale AI projects. Researchers requesting access to Summit must pursue projects that are “expected to be at a scale that require at least 20% of the Summit system.” However, NAIRR projects will only have access to Summit for a limited percentage of its available runtime, and the system will be decommissioned in October 2024, further reducing the overall compute it can provide.
Frontera contains over 17,000 CPUs and 360 GPUs, making it well-suited for CPU-intensive workloads. It is uncommon in industry to use CPUs for AI training or inference, but as previously mentioned, these general-purpose resources are used for different types of scientific research. Given the quantity of hardware available, they can be used for AI projects, albeit with less efficiency and more technical challenges than resources developed specifically for AI workloads.
Delta contains over 800 GPUs and 200 CPUs, and consists of four different configurations that can help optimize for different workflows, including machine learning. Notably, only “a portion of Delta is available for allocation” through the NAIRR pilot, but it is unclear how much that reduces the overall compute.
Figure 1. NAIRR Compute Resources (FLOPS Capacity)
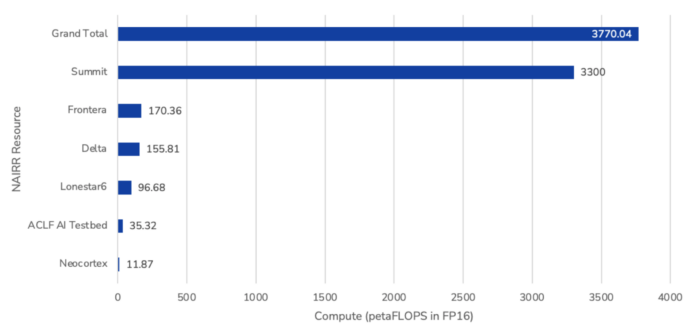
Source: See the CSET Github and Table 1 for details on the calculations and sources.
Note: One of the systems in the ACLF AI Testbed does not support half-precision FLOPs, and is therefore not included in the above compute counts.
The Lonestar6 resource also provides significant compute, though at a much smaller scale than Summit, Frontera, and Delta. It contains over 250 GPUs and 1,000 CPUs. Similar to the Delta resource, compute from Lonestar6 is not fully available through the NAIRR Pilot. Only small CPU requests (in addition to GPU requests) will be allowed for Lonestar6, but it is unclear how much this reduces the overall compute.
Unlike the other resources, the ACLF AI Testbed and Neocortex do not contain GPUs, but instead use novel systems that are designed for AI workloads. For example, both resources include specialized AI accelerators and software that make it easier to integrate machine learning frameworks and deploy models. This can allow for greater customization, reduce the time required to train AI models, and increase the speed of running models. This optimization is not reflected in the raw compute numbers.
The NAIRR allocations page details which AI projects have access to specific NAIRR resources, and for what periods of time (measured in node hours and GPU hours). As displayed in Figure 2, the overall compute allocated to AI projects is roughly 3.2 yottaFLOPs. If all allocated compute was dedicated to a single training run, then it is likely sufficient to train large language models like GPT-3.5, Claude 2, and Llama 2-70B (assuming it is used efficiently and without errors during training). However, this compute is not sufficient to train models like Gemini 1.0 Ultra or GPT-4, which used more than 3.2 yottaFLOPs to train, and the allocated compute is spread across multiple resources and many AI projects.
Figure 2. Allocation of NAIRR Compute Resources (FLOPs)
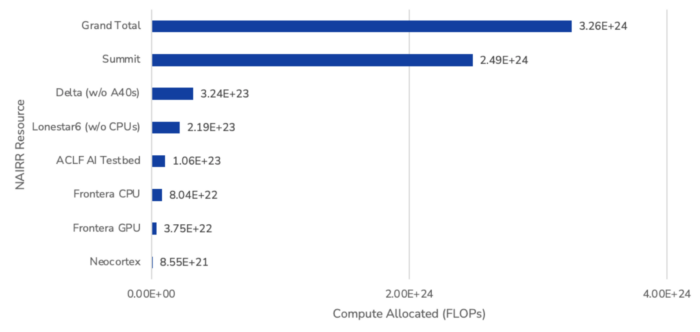
Source: See the CSET Github and Table 1 for details on the calculations and sources.
Note: One of the systems in the ACLF AI Testbed does not support half-precision FLOPs, and is therefore not included in the above compute counts.
Training Foundation Models with NAIRR Compute
One way to assess these compute contributions is by determining whether the NAIRR pilot could support some of the most computationally demanding AI R&D—training large foundation models. In Figure 3, we estimate how long it would take to train five prominent models developed by Google, OpenAI, Anthropic, and Meta, using either the total NAIRR compute or that of individual resources. Although these resources will likely be used to support many different types of AI projects, the below estimates help us broadly gauge their utility at the frontier of AI development (an area that is typically out of reach for less well-resourced organizations). Note that this section does not consider the amount of time the resources are available. We only gauge how the resources could be used to train large foundation models if they were fully available.
Figure 3. Days to Train Foundation Models with NAIRR Compute
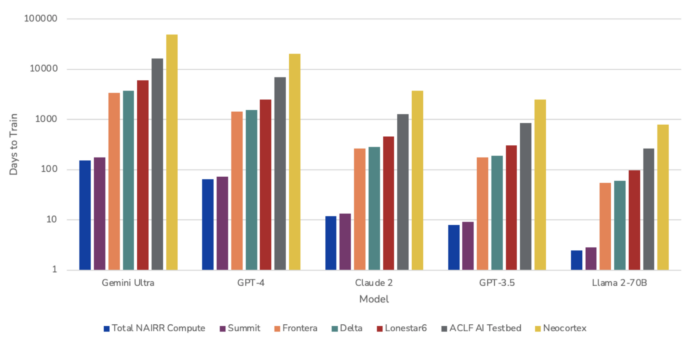
Source: CSET calculations.
Note: (a.) The Epoch AI database of notable machine learning systems was used to get estimates on the compute used, and the time it took, to train the models. However, it does not specify what precision the models were trained in. We assume the models were trained in half-precision. (b.) We do not consider memory, and assume that each resource has sufficient memory to load the models for training. (c.) We assume full hardware utilization.
The highest performing models, Gemini Ultra and GPT-4, would take approximately 153 and 64 days to train using all of the NAIRR pilot’s compute, which is somewhat on par with the time it took Google and OpenAI to train the models (100 and 95 days, respectively). This suggests that the total NAIRR compute, if fully utilized, is roughly equivalent to the compute used by these companies during training. However, hardware is almost never fully utilized, so it would likely take longer to train these models with NAIRR resources. Therefore, the hardware used by these companies likely exceeds that of the NAIRR. For the smallest model, Llama 2-70B, it would only take about two days to train, far surpassing the estimated 90 days it took Meta to train the model. This suggests that the overall NAIRR compute, if fully utilized, is greater than the compute used by Meta to train Llama 2-70B, which occurred before Meta announced bulk purchases of H100 GPUs in 2024.
But as previously stated, no single project can or will be allocated all NAIRR compute. For this reason, we compare time equivalents to individual resources, although they too will likely be used to support several projects. With the largest resource, the Summit supercomputer, it would take about 175 and 73 days to train Gemini Ultra and GPT-4, respectively. This suggests it could be used for training models at this scale. The Summit, Frontera, and Delta could also be used to train smaller models such as Llama 2-70B.
Most resources may not be well suited for large training workloads. For example, it would take several years to train Gemini Ultra or GPT-4 on the Frontera, Delta, Lonestar6, ACLF AI Testbed, or Neocortex resources. These resources are better suited for training smaller models, or other types of AI research and experimentation. This is more apparent when we assess specific systems within these resources. For example, the ACLF AI Testbed contains a GroqRack designed specifically for running model inference, not training.
Limitations
There are limitations to how we assess NAIRR compute and what can be inferred from the data, as we describe here:
- FLOPS alone do not capture the heterogeneity of systems across the NAIRR resources. These resources often use different hardware and software that are networked together in distinct ways, and optimized for different computations and tasks. For example, some resources are used for scientific modeling and simulation, but the technical requirements for efficiently running simulations can differ from deep learning. Supercomputers, including those in the NAIRR pilot, are often designed with bespoke architectures that make it more challenging to scale up AI workloads. We do not consider these differences and challenges in detail, and only broadly consider performance measured in FLOPS.
- We do not consider the memory available in the NAIRR pilot. For the larger resources, the amount of memory available is likely sufficient to load the largest models developed to date. However, a more detailed analysis should include the memory of each resource, and an assessment of what AI models (of varying sizes) can be loaded, trained, and run on the hardware.
- We assess total compute across the whole NAIRR pilot, but no AI project will ever be allocated all of the compute because the resources are split across six Federal computing centers. Moreover, individual resources will also likely support several AI projects. Our estimates only consider the utility of these resources in support of single projects (e.g., training GPT-4).
- We use the Epoch AI database to estimate the compute and time required to train various foundation models, but there are several assumptions baked into the calculations. Information on the compute used (and the time it took) to train most of these models has not been disclosed by the developers, and is instead based on calculations made by outside researchers. We rely on this data, but recognize that there is a degree of necessary speculation in the calculations. Moreover, these calculations do not account for technical challenges and issues that may arise during AI training, especially on general-purpose systems not optimized for AI workloads.
- Our calculations assume full utilization of the NAIRR hardware, but this is uncommon. A more detailed analysis should consider how different degrees of hardware utilization can impact the overall compute capacity of the NAIRR resources, as well as how long it would take to train models on the hardware.
Conclusion
These estimates suggest that the NAIRR pilot is a significant first step in providing compute to under-resourced organizations, although it is still a fraction of what industry is presently using to train large models. Training some large models with NAIRR resources is possible but only at the scale of a few times per year, suggesting that broad access to compute resources for researchers is still limited. Importantly, different resources are suited for different purposes, their overall utility depends on many factors beyond raw computational capacity, and the allocated GPU and node hours are spread across many different AI projects. Ultimately, the extent to which the NAIRR pilot helps close the gap between well-resourced companies and more resource-constrained organizations and academic institutions remains an open question.
NAIRR Resource Overview
Table 1. NAIRR Compute and Hardware
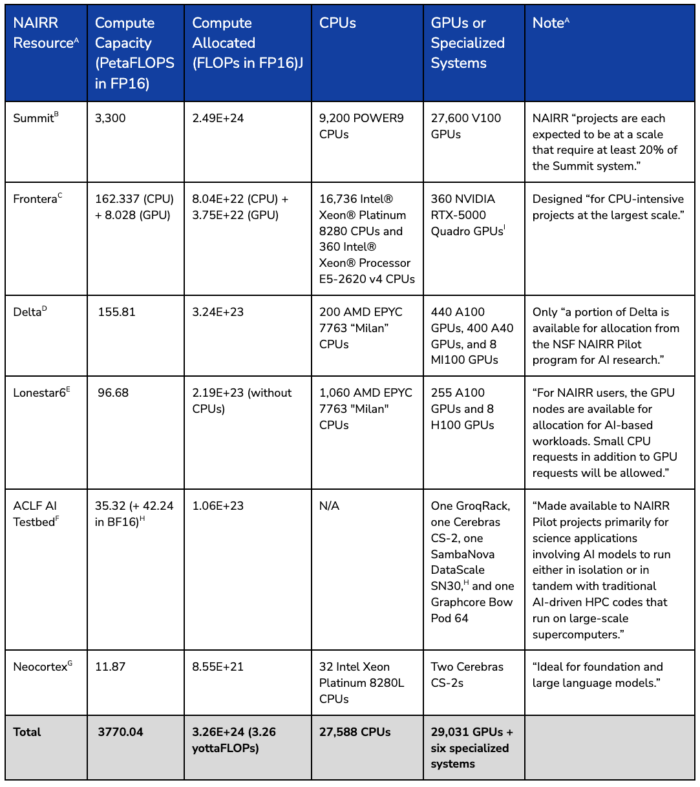
Sources: (A.) “Advanced Computing Allocations to Advance AI Research and Education,” NAIRR Pilot, accessed February 2024, https://nairrpilot.org/allocations.
(B.) Tom Papatheodore, “Summit Architecture Overview,” Oak Ridge National Laboratory, May 20, 2019, https://www.olcf.ornl.gov/wp-content/uploads/2019/05/Summit_System_Overview_20190520.pdf; “SUMMIT Oak Ridge National Laboratory’s 200 petaflop supercomputer,” Oak Ridge National Laboratory, accessed March 2024, https://www.olcf.ornl.gov/olcf-resources/compute-systems/summit/.
(C.) “FRONTERA – The Fastest Academic Supercomputer in the U.S.,” TACC, accessed March 2024, https://tacc.utexas.edu/systems/frontera/; “Intel® Xeon® Platinum 8280 Processor,” Intel, accessed March 2024, https://ark.intel.com/content/www/us/en/ark/products/192478/intel-xeon-platinum-8280-processor-38-5m-cache-2-70-ghz.html; “Intel® Xeon® Processor E5-2620 v4,” Intel, accessed April 2024, https://www.intel.com/content/www/us/en/products/sku/92986/intel-xeon-processor-e52620-v4-20m-cache-2-10-ghz/specifications.html; “NVIDIA Quadro RTX 5000,” TechPowerUp, accessed April 2024, https://www.techpowerup.com/gpu-specs/quadro-rtx-5000.c3308; “THE WORLD’S FIRST RAY TRACING GPU: NVIDIA QUADRO RTX 5000,” NVIDIA, accessed May 2024, https://www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/quadro-product-literature/quadro-rtx-5000-data-sheet-us-nvidia-704120-r4-web.pdf.
(D.) “Delta Project Profile,” NCSA, accessed March 2024, https://www.ncsa.illinois.edu/research/project-highlights/delta/; Oliver Peckham, “NCSA’s Delta System Enters Full Production,” HPCwire, October 2022, https://www.hpcwire.com/2022/10/05/ncsas-delta-system-enters-full-production/; “AMD EPYC™ 7763,” AMD, accessed March 2024, https://www.amd.com/en/products/cpu/amd-epyc-7763; “NVIDIA A100 TENSOR CORE GPU,” NVIDIA, accessed May 2024, https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-nvidia-us-2188504-web.pdf.
(E.) “LONESTAR6 USER GUIDE,” TACC, February 15, 2024, https://docs.tacc.utexas.edu/hpc/lonestar6/#intro; “TACC’s Lonestar6 Supercomputer Gets GPU and Server Boost,” HPCwire, November 14, 2022, https://www.hpcwire.com/off-the-wire/taccs-lonestar6-supercomputer-gets-gpu-and-server-boost/; “NVIDIA H100 Tensor Core GPU,” NVIDIA, accessed May 2024, https://resources.nvidia.com/en-us-tensor-core/nvidia-tensor-core-gpu-datasheet.
(F.)”ALCF AI Testbed,” Argonne Leadership Computing Facility, accessed March 2024, https://www.alcf.anl.gov/alcf-ai-testbed.
(G.) “Neocortex,” HPC AI and Big Data Group – Pittsburgh Supercomputing Center, accessed March 2024, https://www.cmu.edu/psc/aibd/neocortex/; “Intel® Xeon® Platinum 8280L Processor,” Intel, accessed March 2024, https://www.intel.com/content/www/us/en/products/sku/192472/intel-xeon-platinum-8280l-processor-38-5m-cache-2-70-ghz/specifications.html.
(H.) Note: we could not find specifications on the SambaNova DataScale SN30’s FLOPS performance in FP16.
(I.) Note: we used non-tensor FP16 FLOPS for the Quadro RTX 5000 because we could not find a source that provided the precision of the tensor performance.
(J.) Compute allocations (FLOPs) are calculated by multiplying the FLOPS of a resource by the amount of time (GPU or node hours converted to seconds) it is allocated to AI projects, then dividing that number by the amount of nodes or GPUs in the resource; “Current Projects,” NAIRR Pilot, accessed June 2024, https://submit-nairr.xras.org/current-projects.
—
Thanks to Brian Love, Kyle Crichton, John Bansemer, Colin Shea-Blymyer, and Tim Fist for their feedback and support with calculations in this post.
This blog post was updated on August 19, 2024, to incorporate the amount of time (GPU hours and node hours) that initial NAIRR resources were allocated toward AI projects.