This is the second installment of a three-part blog series. To read the first part, click here. And to read the third part, click here.

In this explainer:
- Why pre-training (learning to predict the next word based on a broad dataset) only gets you so far.
- The methods AI developers use to go beyond pre-training.
- Using AI to train AI.
Large language models (LLMs) are often characterized as predicting the most likely next word based on massive, internet-scraped text datasets. For the majority of LLMs used today, however, this is an incomplete description. In the previous explainer in this series, we explained how models are pre-trained on very large text datasets to predict the word that most likely comes next. Although this approach is very powerful, pre-trained models can be difficult to use and produce harmful outputs. In response, researchers have developed a variety of “fine-tuning” techniques that modify pre-trained models and change the types of outputs they are likely to produce.
This post explains two common types of fine-tuning methods. First, we describe supervised fine-tuning, which can be used to train a model to be especially good at predicting a particular kind of data. Second, we explain how reinforcement learning methods such as reinforcement learning from human feedback and Constitutional AI work, why they’re so useful, and why they produce models that can’t be accurately described as simply predicting the most likely next word.
All of these methods—especially those based on reinforcement learning—are new, and are under active development and experimentation by AI researchers. As with many topics related to cutting-edge AI systems, experts have a limited understanding of exactly how different fine-tuning methods affect models and where exactly they will fail. Nonetheless, these techniques underpin LLM-based products that are being used by hundreds of millions of people. Accordingly, we believe it is valuable for policymakers and the public to understand what these techniques are and why they are used.
Why Use Fine-Tuning? The Limitations of Pre-trained Models
As we saw in the previous post in this series, pre-trained models can perform a wide range of tasks despite being trained only to predict what word comes next based on large, messy datasets. This makes pre-trained models very useful. However, they have several important flaws that limit their usefulness and create risks for their deployment.
First, pre-trained models do not always respond as users might expect. Because pre-trained models are simply trying to predict which word comes next, they do not necessarily interpret user input as an instruction or question. For example, when prompting the pre-trained-only version of GPT-3 with, “What is the capital of France?” it may produce “ (2 points)” so that the final output looks like “What is the capital of France? (2 points).” In this particular instance, GPT-3 determined that the most likely place for this text to appear was not as a sincere question to be answered, but as an exam question with a point value. The model therefore completed the pattern, rather than answering the question as a user might expect. Behavior like this is a natural consequence of the model trying to produce text that is similar to its training data, and similar examples are common. Experts can use prompt engineering techniques to get useful output out of models that behave like this, but needing to use such techniques makes the models much less accessible to the general public.
Second, pre-trained models may mimic harmful characteristics of the training data. The internet is full of racist, bigoted, and sexist text, so pre-trained models may themselves exhibit those characteristics, such as by associating words related to Islam with violence and terrorism. They may also produce expletives or other toxic text and can mimic falsehoods present in the training data. For example, researchers found that the pre-trained GPT-3 model sometimes claims that frequent knuckle cracking can lead to arthritis (it cannot, though this is a common misconception).
Third, pre-trained models can produce plausible yet false outputs. Pre-trained LLMs are often good at producing a plausible-sounding answer, even when they cannot predict the right one. For example, an LLM prompted to give sources for a claim may invent plausible-sounding yet fake citations to academic research, rather than giving correct citations or simply saying that it doesn’t know of any sources. This problem is often known as “hallucination.”
Fourth, pre-trained models may help malicious users cause harm. For example, pre-release versions of GPT-4 would provide advice on how to buy unlicensed guns, launder money, and synthesize dangerous chemicals. So far, it does not appear that current LLMs provide information that is any more dangerous or accessible than what is available through search engines. But if more advanced LLMs in the future are more capable in areas such as scientific reasoning and long-range planning, this problem may increase in importance.
Finally, pre-training datasets may not contain information related to specific use cases. This can present an obstacle in areas where that data is essential for achieving good performance for that use case. For example, some companies may want their internal LLMs to know details from internal corporate datasets that the pre-training data would not include. By the time they are released, LLMs may also not be trained on the latest information, making them unable to converse on the most recent developments.
In benign cases, these limitations merely make LLMs difficult to use. In more extreme cases, they could cause harm to users or enable bad actors to harm others. Overall, they present significant obstacles to the deployment of large LLMs, and have motivated LLM developers to invest in techniques that can overcome them. While the techniques we describe below do not currently resolve all of the problems above, they can reduce their likelihood and severity.
Fine-Tuning Methods
AI developers use the phrase “fine-tuning” to refer to methods that take a pre-trained model and refine it towards some particular purpose. Fine-tuning typically uses significantly fewer computational resources than pre-training, but is just as important to producing useful LLMs. For example, the use of fine-tuning methods is considered to be a major reason why ChatGPT was initially so much more successful than other similar chatbots. There are several common types of fine-tuning methods.
Supervised Fine-Tuning
Supervised fine-tuning involves collecting or creating a dataset of carefully curated text. Starting with a model pre-trained on a very large amount of text from the internet, this curated dataset is used in a second, smaller round of training to modify (i.e., fine-tune) the model to better predict that text. Fine-tuning datasets are much smaller than the enormous volumes of data used for pre-training and contain examples of how the model should ideally complete text, rather than the unwieldy range of text types and subjects found in pre-training datasets. Fine-tuning on this kind of focused, curated data often results in models that are better at related tasks than models purely pre-trained to predict many different types of text.
Task-specific fine-tuning involves collecting human-written examples of a specific task that an LLM should accomplish. For example, a model fine-tuned on a dataset of plays by Shakespeare is better able to produce Shakespeare-like outputs. Even if the model already saw Shakespeare in its original training data, fine-tuning exclusively on Shakespeare will make the model much more likely to produce Shakespeare-like output. Task-specific fine-tuning can also be used by enterprises that want to create LLMs trained on their own proprietary data. For example, business credit card company Brex uses fine-tuning to more effectively generate expense memos.
Instruction fine-tuning uses a dataset of examples of a user giving an instruction and the model carrying it out. This dataset may be written by humans or more advanced LLMs. The purpose of this kind of fine-tuning is to make models respond to instructions in general, rather than to complete a particular task. This step can reduce problems associated with models trained to predict internet text rather than produce coherent responses to an instruction. Instruction fine-tuning can make models much more useful and is used in most commercially deployed models.
It would be impossible to produce enough task-specific or instruction fine-tuning data to train an LLM from scratch, which is why these methods always start with pre-trained models. As we described previously, pre-training allows models to develop a statistical representation of language, facts about the world, and other information, which serves as a powerful foundation that makes it possible for them to learn from a relatively small amount of fine-tuning data. You can think of fine-tuning as a way to channel and refine the raw capabilities learned during pre-training.
Supervised fine-tuning does have notable limitations. First, it still requires a large amount of text to be curated or written by humans, which can be very expensive and difficult to collect. Second, the standard methods for supervised fine-tuning do not provide a way for developers to train a model to avoid producing especially bad outputs. Third, supervised fine-tuning can only teach an LLM to mimic—not exceed—human performance. If humans frequently make errors on the task, the model will learn to imitate those errors. At its core, supervised fine-tuning still trains models to predict the most likely word to come next, albeit based on more specific data than a model that has only been pre-trained.
Reinforcement Learning For LLMs
Reinforcement learning is an approach to AI that has shown promise in many applications outside of LLMs. Instead of training models to imitate a dataset, reinforcement learning works by training models to maximize a chosen measure of task performance (referred to as a reward signal). Reinforcement learning has powered systems that can beat the world champion in Go, outperform humans at drone racing, and help design computer chips.
Reinforcement learning methods for LLMs are being used to address some of the shortcomings of pre-trained models and supervised fine-tuning. These methods do not necessarily require collecting human demonstrations and can more effectively reduce the probability that models produce very bad outputs. In addition, reinforcement learning can be used to train models that outperform humans on a task, especially if (as in Go) there is a way to easily verify excellent performance. It is thus natural to think that reinforcement learning could be used to resolve those problems in LLMs, too.
The major barrier to training LLMs using reinforcement learning is that it requires a reward signal, a quantitative indicator of how good or bad the AI’s performance is. In Go, the reward signal is based on whether the AI system wins the game. In drone racing, the reward signal can be programmed to be highest when the drone is progressing fastest towards the next racing gate while keeping the gate in its field of vision. In cases like these, it is relatively easy to specify a reward signal and program it into the system.
Creating a reward signal is notoriously difficult for more complex tasks. While it is easy to write code to determine who won a game of Go based on the game state, it would be nearly impossible to manually program a reward signal for the nebulous concept “follow instructions, without producing toxic, damaging, or harmful outputs,” which is what LLM developers are interested in.
Instead, LLM researchers who want to use reinforcement learning start by training special machine learning models, called reward models, to provide a reward signal. These reward models take in some text and estimate how good it is, usually by providing a numerical score that can serve as the reward signal for reinforcement learning.
This approach shifts the challenge from manually specifying a reward signal to instead needing to find a way to train the reward model. To do this, LLM developers collect data specifically for training their reward models. Two common methods for collecting this data are to use human feedback and AI feedback.
Reinforcement Learning from Human Feedback (RLHF)
Originally developed by OpenAI, reinforcement learning from human feedback (RLHF) was an important element of how ChatGPT was developed. At its simplest, RLHF works by having human annotators compare two different model-generated responses to a prompt and choose which is better.1 Annotators typically rate responses according to instructions provided by model developers. This may include giving higher ratings to responses that better follow instructions, exhibit less biased language, and best refuse requests for harmful information.
This human-produced data is used to train a reward model, which is essentially a machine learning model that takes in some text and gives a score for how good it is. Once the reward model is trained, the scores it produces are used as the reward signal to train the original LLM with reinforcement learning. This overall scheme is what the term “RLHF” refers to. Models fine-tuned in this way are often much better at following instructions and avoiding undesirable outputs. In some cases, they can even outperform humans at the tasks they are trained on.2 It is also much simpler (and thus cheaper) for data annotators to rank different responses than it is for them to write original responses, as is often necessary in supervised fine-tuning.
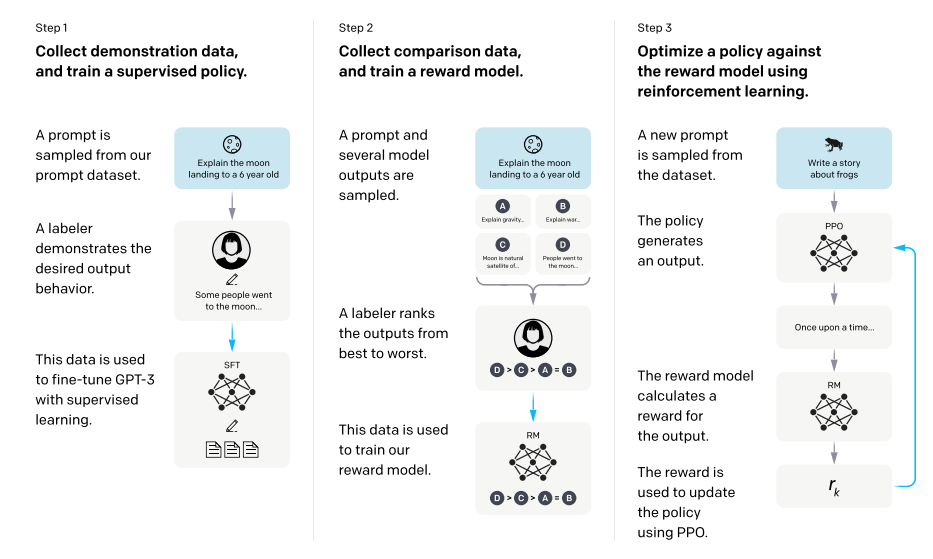
Source: OpenAI’s fine-tuning pipeline, public as of 2022, which includes supervised instruction fine-tuning (step one) and RLHF (steps 2-3).
While RLHF is useful in practice, it still has limitations. First, human feedback is difficult to collect and is hardly perfect. Feedback may be expensive to collect, and human annotators can make mistakes. Reasonable annotators may also disagree about how a response should be rated, including as a result of demographic factors, which makes it important to select representative annotators.
Second, as models improve, it becomes increasingly difficult to accurately evaluate their outputs. For instance, as models are able to summarize ever-longer documents, it becomes harder for humans to evaluate those summaries. In some cases where models outperform humans at a task, humans may be ill-equipped to evaluate outputs. As models produce increasingly complex outputs, RLHF’s approval-driven mechanism could even result in models that produce outputs that merely seem good to human raters.
Reinforcement Learning from AI Feedback (RLAIF)
Reinforcement Learning From AI Feedback (RLAIF) is one attempt to improve upon RLHF. It operates just like RLHF, except that instead of human annotators ranking different LLM responses to train the reward model, an LLM provides the rankings instead. Just like human annotators, the LLM is provided with written instructions on how to rate outputs.
RLAIF is part of a broader trend to increasingly use AI models to supervise, evaluate, and improve AI models. This can be cheaper, faster, and more efficient than paying humans to do it. There is also some hope that in the future, LLMs may be able to evaluate each other on complex tasks that humans are not able to evaluate well, such as analyzing very long documents or answering technical questions beyond the expertise of most humans.
For example, consider Anthropic’s fine-tuning pipeline, which they call “Constitutional AI,” pictured in the diagram below. First, Anthropic fine-tunes an LLM with RLHF to be as “helpful” as possible, meaning that the model always follows instructions, even if they are harmful. Second, it prompts the model with human-written “red teaming” prompts designed to elicit harmful responses. Third, it asks the model to critique its own responses, and revise them to be less harmful. Fourth, the dataset of prompts and revised responses is used to fine-tune the model. Finally, RLAIF is used to further fine-tune the model to be less harmful.
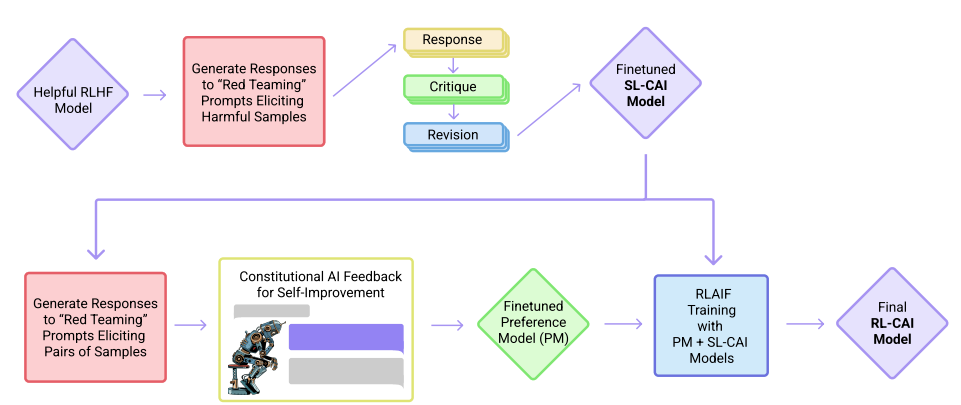
Source: Anthropic’s Constitutional AI Pipeline, public as of 2022, which includes RLAIF and RLHF
It takes a lot of time and research effort to design and test these techniques, despite the level of automation that has already been achieved. Some developers are hoping to go even further. OpenAI has stated that their goal for steering systems in the future is to build a “human-level automated alignment researcher” that can generate not just data, but also the algorithms used to steer (“align”) models. If successful, this kind of approach would be another big step in the direction of using AI to build and evaluate AI.
These processes might seem surprisingly convoluted, and in many ways, they are. Researchers are throwing together increasingly complex and circular mechanisms to try to steer LLMs in the right direction. They can devise tests for those mechanisms to see how they perform in a controlled environment, but the full implications of this complexity, like much about LLMs, are still not completely understood. The trend towards using AI to develop and test AI makes these challenges even more intense.
Limitations of Fine-Tuning
Each of the techniques detailed above has been important in enabling AI developers to turn LLMs from a niche technology used primarily by computer scientists into a usable consumer product. However, existing fine-tuning techniques cannot currently guarantee that models will behave as intended, for several reasons.
First, these techniques provide no guarantees of model behavior, especially in untested situations. The techniques are used because they seem to work, not because there are principled reasons why they should definitely work. Researchers conduct tests to identify situations where models do not behave as they expect, but they cannot find all such cases. Both fine-tuned models, and the reward models used to train them, may not operate as expected in novel situations, a problem known as out of distribution generalization. More generally, fine-tuning can have unanticipated effects, as when a late 2023 update to ChatGPT appeared to have made the model “lazier,” meaning that it was more prone to refusing to complete long tasks. (A later update appears to have fixed the problem.) There are currently no settled best practices for fine-tuning, and the methods used are rapidly evolving and often combined. There are already many methods competing with RLHF and RLAIF that we could not fit into this explainer.
Second, fine-tuning can be circumvented by malicious actors. “Jailbreaks,” where models are “tricked” into providing harmful or disallowed responses, is one example of this kind of circumvention. Another is research showing that models can be further fine-tuned by adversarial actors to undo their initial fine-tuning, or in some cases it can even be removed accidentally. Both of these limitations show that current fine-tuning techniques do not remove harmful model capabilities, but rather cause the models not to express them in most circumstances. As explored in an earlier CSET primer, commercial providers of LLMs do have other tools at their disposal to control what their models will output (such as filters to block undesirable prompts or outputs), but these tools are also imperfect. Further work will be needed to develop techniques that robustly work as intended.
Conclusion
In this explainer, we have covered two of the most common techniques for addressing the problems with pre-trained LLMs: supervised fine-tuning and reinforcement learning-based fine-tuning. Both methods can make models more helpful and less likely to produce harmful text, though they have limitations.
Because of fine-tuning methods, most LLMs in use today can’t really be described as predicting the next word based exclusively on internet text. Instead, LLMs are steered—only somewhat reliably—to output text that meets developer specifications. The methods used to steer these models are evolving rapidly, and techniques increasingly make use of LLMs to guide the outputs of other LLMs. As fine-tuning methods continue to evolve, the way we think about LLMs will have to continue to change with them.
Thanks to John Bansemer, Matt Burtell, Hanna Dohmen, James Dunham, Rachel Freedman, Krystal Jackson, Ben Murphy, and Vikram Venkatram for their feedback on this post.
- Other research has explored asking annotators to give responses a numerical grade or rank more than two responses at a time.
- This works because annotators may not have the time, effort, or ability to perform extremely well at the task themselves, but can evaluate whether the model is performing extremely well or not. To analogize, somebody may be able to tell a good dancer from a bad one even if they are not, themselves, good at dancing.