GitHub is an online platform that acts as a focal point for collaboration and implementation, not just for software development but also for data storage, documentation, and general discussion. Dedicated to open source code and software development, the site makes coding and data projects accessible to anyone who signs up for an account. Coupled with built-in version control tools, GitHub is cemented as the default platform for computer programmers from all over the world. However, China elevated Gitee in 2020 as an alternative for Chinese developers to the Microsoft-owned GitHub. As an open source software site, users can provide code for others to use and build upon in their own projects, making even the most difficult of software implementations as easy as “pip install package.” Information on GitHub can thus provide novel insight into the development and implementation of emerging technologies.
Machine learning (ML) and other advanced technologies are built by translating complex mathematical concepts such as probability, linear algebra, and optimization into software. GitHub is where software engineers store these fundamental translations for others on the platform to use. While intellectual property laws protect highly advanced machine learning models, their most basic forms often exist publicly on GitHub. Public GitHub implementations allow any user to perform machine learning on a given dataset without needing to code the algorithms themselves. This reduces development time and overall implementation costs, enabling a wider range of use cases. GitHub users can test out new applications, such as machine learning, and contribute to the advancement of the field.
Figure 1. How Developers Interact on GitHub
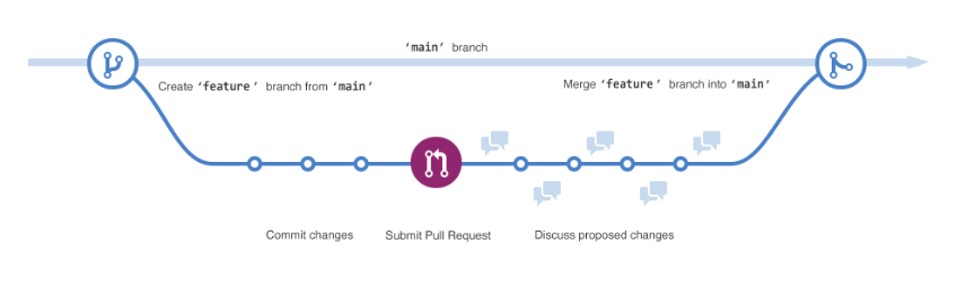
GitHub’s popularity stems in part from its version control tools. Version control allows users to test out changes from collaborators on a set of code within a repository, which stores all files, folders, and resources of interest for the project. New lines of development extend out from the foundational working version (“main”), either through branches for vetted collaborators or forks for the rest of the community, as seen in Figure 1. Managers for the repository decide whether to commit these updates to the main branch. The ability to experiment with changes and revert to earlier working versions encourages software development as it offers both damage control and collaboration facilitation. GitHub tracks every instance of such collaboration—each contribution and eventual “commit” to a repository is recorded as metadata. Furthermore, GitHub records broader information on each repository, including ownership, issues, and dependencies. This metadata from GitHub offers insight into the development ecosystem for a given repository.
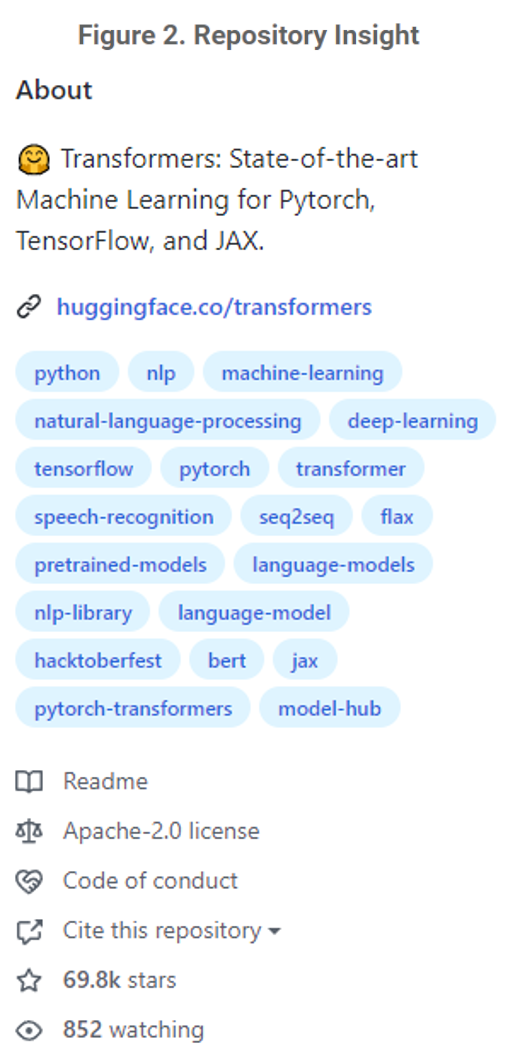
To capture that insight, CSET collected a dataset of GitHub repositories. Our GitHub repository dataset currently includes 291,264 unique repositories, along with their associated metadata, from the present day back to 2008. Given that GitHub spans various application areas, our team elected to include a repository only if either (1) a publication within CSET’s merged corpus of scholarly literature references the repository or (2) the repository has an AI-relevant topic tag (see Figure 2).1 The topic tags were manually curated by CSET researchers, including, for example, “machine-learning” and “unsupervised-learning.” Through a combination of GitHub’s API and manual scraping, our team collects the metadata for each repository and updates it monthly. However, due to the nature of GitHub, our team is only able to collect information on public repositories, limiting the set of available projects.
Analyzing public source software allows researchers to track the proliferation of emerging technologies. The pipeline between academic research and widespread application can be viewed through GitHub, especially in combination with other datasets. For example, public and private entities can verify their GitHub accounts, providing researchers with the means to track organizational software development. Coupling this development tracking with organizational information from related CSET datasets provides further insight on the technology ecosystem. Furthermore, the collection of collaborative activity provides insight into the development network for each repository, allowing researchers to track collaboration on key emerging technologies.
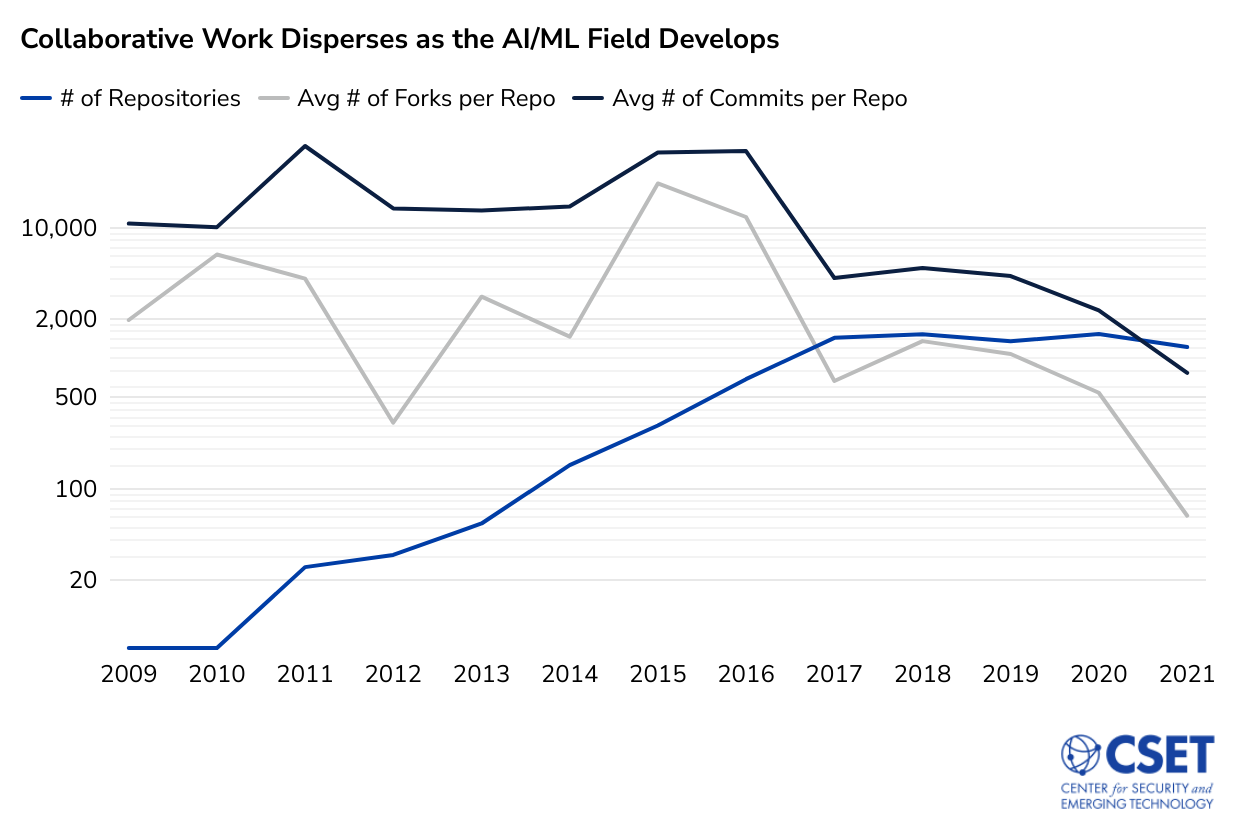
Figure 3. Collaborative Work Disperses as the AI/ML Field Develops
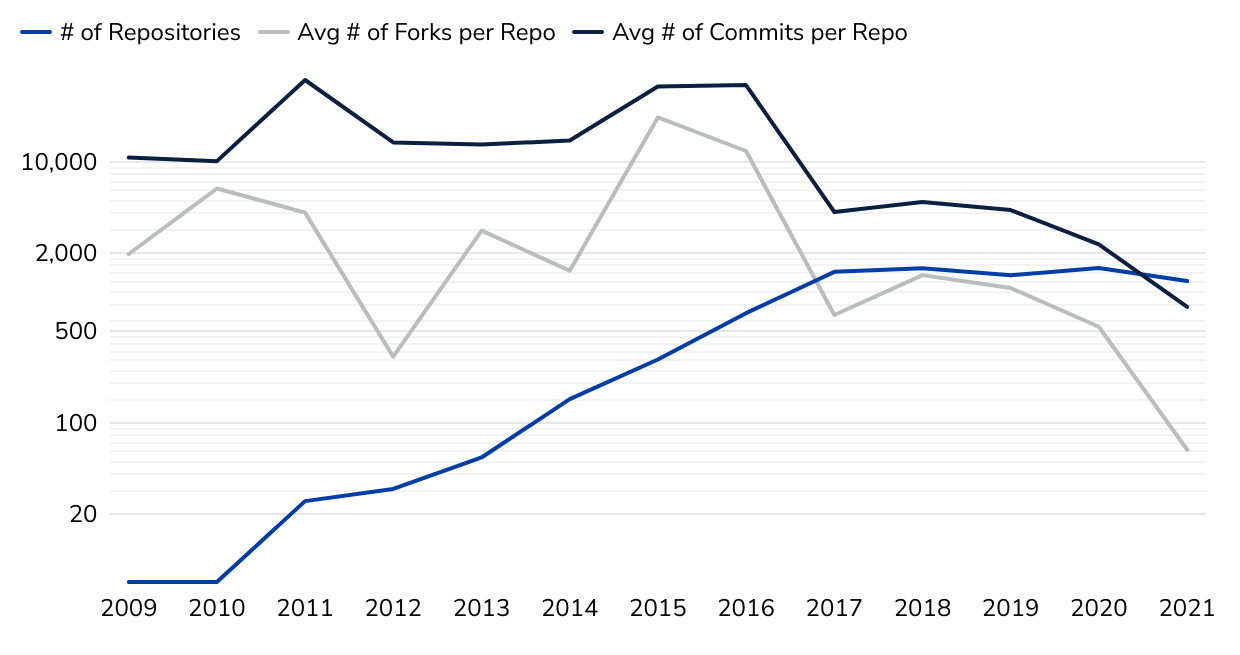
For example, Figure 3 shows the total number of repositories in our dataset containing artificial intelligence or ML topic tags with more than three distinct contributors, as well as the average number of forks per repository and the average number of commits per repository over time. The explosion in the number of repositories tagged as AI/ML tracks with what we know from scholarly literature, patents, and grants—the field has grown dramatically over the past decade. However, the dive in average forks and commits per repository suggests that collaborative activity within these repositories is on the decline. When the field first emerged on GitHub, we saw developers working together frequently on relatively few repositories. As new projects and techniques were developed, development dispersed.
Want to learn more about GitHub? Check out this tutorial or this guide.
- CSET merged corpus of scholarly literature including Digital Science Dimensions (an inter-linked research information system provided by Digital Science (http://www.dimensions.ai), Clarivate’s Web of Science, Microsoft Academic Graph, China National Knowledge Infrastructure, arXiv, and Papers With Code. All China National Knowledge Infrastructure content is furnished for use in the United States by East View Information Services, Minneapolis, MN, USA.