In 2022 and 2023, the Bureau of Industry and Security (BIS) at the U.S. Department of Commerce introduced and later expanded export controls to restrict the highest-performing AI chips from being exported to China. BIS likely did not intend to control CPUs (central processing units, also called general-purpose processors) with these restrictions. However, CPU designers increasingly incorporate specialized units for AI computation into CPUs, causing some to trigger export licensing requirements.1
Summary
Although some CPUs are already subject to the latest regulations (“AI-capable CPUs”), the rules were not designed to control them. When deciding whether to carve out CPUs from the controls, BIS should keep in mind the following considerations:
- U.S. chip designers will likely easily develop versions of controlled CPUs for the Chinese market by disabling key matrix extensions.
- Chinese companies may increasingly and preemptively switch to domestically-designed CPUs as they fear being cut off from U.S. processors. This may also accelerate China’s development of domestic CPUs.
- U.S. CPU designers could face significant hits to revenue, which risks hampering their competitive edge.
If BIS decides to continue controlling AI-capable CPUs, we make the following recommendations:
- BIS should develop a red flag for AI-capable CPUs that does not rely on high-bandwidth memory (HBM). Under the current control regime, foundries are required to screen inbound design files for HBM and more than 50 billion transistors to help foundries detect export control evasion. However, CPUs, unlike AI chips, rarely incorporate HBM, making the red flag far less effective for CPUs.
- BIS should provide additional guidance on how to calculate tera (trillion) operations per second (TOPS) for a commercial CPU to avoid confusion and reduce the burden on industry. TOPS—a performance metric that BIS uses to identify controlled AI chips—is not frequently reported for CPUs.
- BIS should evaluate existing controls for licenses and intellectual property (IP) inputs for CPUs, and to the extent they are not already controlled, consider controlling them. The export of Instruction Set Architecture (ISA) licenses and core IP licenses may undermine the controls, increasing the importance of controls on those inputs.
Are CPUs Controlled?
In October 2022, the Biden Administration issued semiconductor export controls designed to deny cutting-edge AI chips to China. In the initial rule and its subsequent update in 2023, BIS listed the types of chips that it intended to be subject to the rule, including graphics processing units (GPU), tensor processing units, application-specific integrated circuits, and others. Notably, BIS did not include CPUs (i.e., general-purpose processors) in that list but did include them in the list for a separate anti-terrorism control, which they updated concurrently.2 The omission of general-purpose processors in the chip controls but not in the anti-terrorism controls suggests that BIS did not intend to control CPUs as part of the former or did not expect that CPUs would reach the control threshold for a number of years. Regardless of the intent from BIS, as the regulation is currently written, a CPU would trigger export licensing requirements if it exceeded the performance thresholds.
To date, we have analyzed over 900 AI chip products—including AI-capable CPUs—to determine whether they are controlled.3 In the interactive table below, we provide an updated snapshot of our analysis, filtered for CPU products.4
Please note that this table is not a compliance tool. We’ve done our due diligence to validate BIS’s three criteria for each product in this spreadsheet—the chip’s total performance, performance density, and whether the chip is “designed or marketed” for use in a data center—using the linked sources in the table below. Companies and third-party sellers of these chips should seek legal advice to help formally determine which licensing policies apply to their products. If you have questions or would like to suggest ways to improve the data, please contact us at cset@georgetown.edu.
Table 1. Select List of Chips and Licensing Policies
Source: CSET analysis of chip datasheets and news articles.
Note: In some cases, we were not able to find the die area, which means we were not able to calculate the performance density for those chips.
Our analysis suggests that a few recently released high-performance CPUs have already triggered the chip controls, whether BIS intended this or not. Specifically, our analysis identifies three Tachyum Prodigy CPUs and Tesla’s D1 chip which may require a full license for export to China. Additionally, 13 of Intel’s Xeon datacenter CPUs appear to be NAC-eligible for export to China, meaning they may require an expedited license.
Figure 1. License Requirements of Controlled CPUs
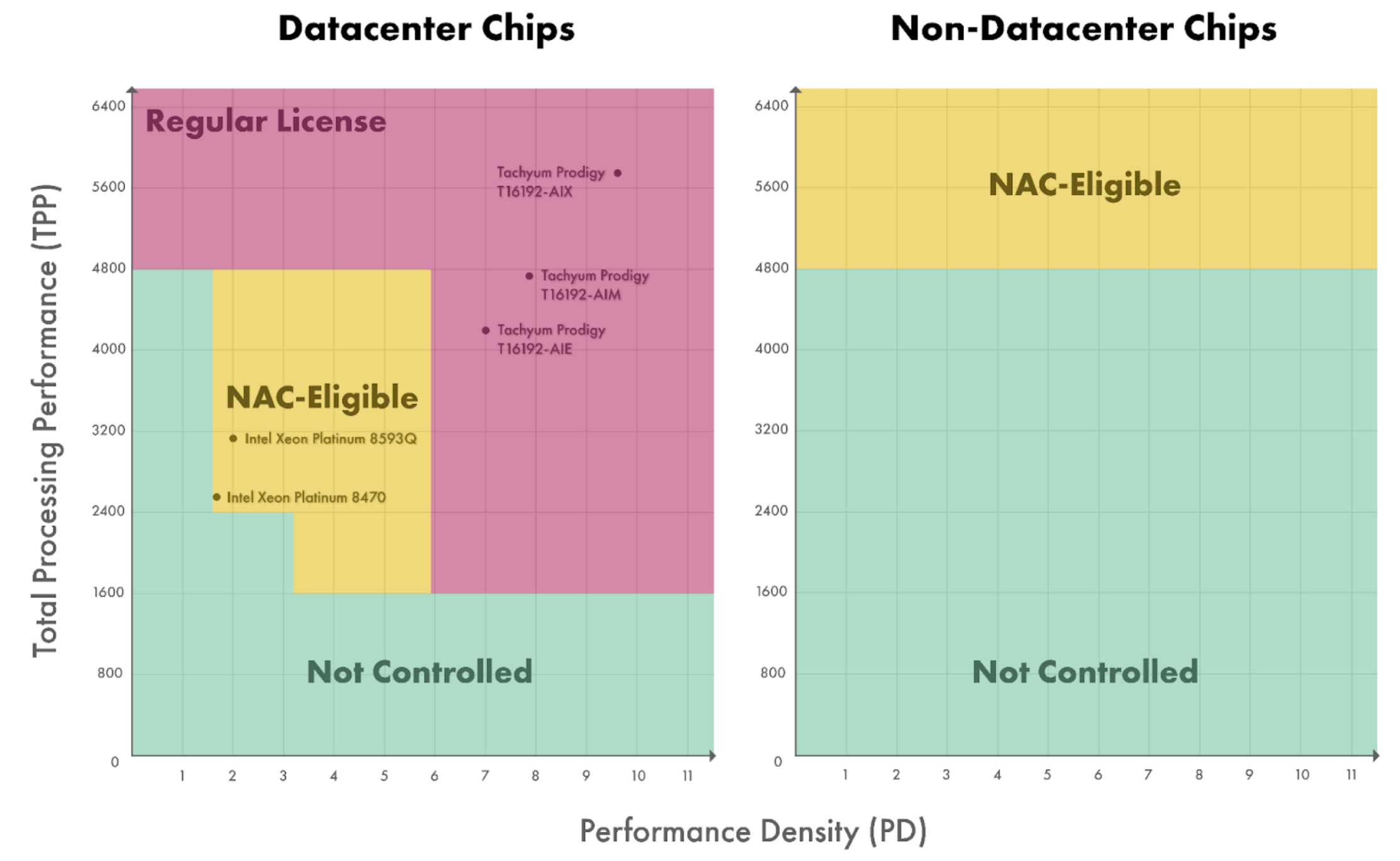
Source: CSET analysis of export control regulations, chip datasheets, and news articles.
CPUs are beginning to exceed the control threshold, largely because chip designers are making them better at AI operations as an alternative to designing specialized AI chips. Typically, when engineers train an AI model and deploy it to users, they offload the computation from a CPU to a specialized AI chip. In these systems, a single CPU will often coordinate the computations being performed by four or more AI chips. However, transferring lots of data between chips can create bottlenecks, which is particularly a problem for deploying AI models (i.e., inference) where latency matters; users expect a rapid response when they query ChatGPT, for example. Also, the computer code needed to offload AI calculations to a specialized chip is more difficult to write than the code used to perform the same calculation on a CPU. Due to these complexities, chip designers are increasingly seeking to improve the performance of CPUs themselves for AI. To accomplish this, chip designers are incorporating elements into CPU cores that are specifically designed to multiply and add matrices, which accelerates AI calculations.5
These performance improvements, in addition to supply constraints on GPUs, are leading some cloud providers to use CPUs for AI calculations.6 For example, Alibaba Cloud, a leading Chinese cloud provider, is advertising Intel’s 5th-generation Xeon CPUs as a viable alternative to dedicated AI chips for deploying AI models to users. Naver, a South Korean cloud provider, is replacing Nvidia’s GPUs with Xeon CPUs as the primary hardware to run certain AI applications in.
Today, there appear to be relatively few CPUs advanced enough to meet the control thresholds, but most of these products were released recently and only achieved volume production in 2024.7 In the coming years, we expect the share of CPUs exceeding the threshold for controls to increase as manufacturing processes continue to advance and demand for AI applications pushes chip designers to improve the performance of CPUs for matrix operations.
Considerations for BIS
Thus far, BIS has not clarified its policy stance on whether the latest semiconductor controls should apply to general-purpose processors. As these processors continue to advance, BIS must grapple with the geopolitical, economic, and national security trade-offs of applying a country-wide control not just on advanced AI chips destined for China but also on an increasingly wider set of CPUs.
BIS is concerned about China’s “development and deployment” of AI models to “further [China’s] goal of surpassing the military capabilities of the United States and its allies.” Relative to the current policy, carving out CPUs from the controls would likely make more chips available for AI deployment and may indirectly make more chips available for AI development. Specifically, since these CPUs can be used for AI deployment (i.e., inference), carving them out of the controls would directly increase the number of chips available to China for AI deployment. Furthermore, these CPUs could replace the AI chips that China is currently using for AI deployment, which, in turn, would free up China’s limited AI chip supply for developing new models.
If BIS does not carve out CPUs from existing controls, in the short term, we expect U.S. CPU designers, such as Intel and AMD, will likely quickly develop chips designed for the Chinese market by disabling key vector or matrix extensions. This has been done before; Intel disabled a vector extension on its 2021 Alder Lake CPUs—first using microcode and later by physically fusing it off. Similarly, after the October 2022 export controls took effect, GPU designers disabled interconnect channels and computation cores to sell lower-performance AI chips into China.8 These actions would allow U.S. companies to continue drawing revenue from Chinese markets while complying with the rules.
At the same time, the existing controls on AI-capable CPUs could also push additional revenue towards Chinese CPU designers, potentially increasing the pace at which they can develop domestic alternatives. Even targeted restrictions on the highest-performing CPUs would likely increase Chinese companies’ fear that they would be cut off from a wider swath of U.S. processors, encouraging them to seek domestic alternatives. Chinese companies that currently prefer and rely on U.S. CPUs may turn to CPUs designed by Loongson, T-Head, or HiSilicon instead. This will likely impact the revenues of American CPU designers; 27 percent of Intel’s 2023 revenue came from China.9 In the long term, these dynamics risk undermining U.S. leverage and could hamper U.S. CPU designers’ competitive edge. This incentive will only grow as CPUs continue to advance and increasingly pass the control thresholds.
Recommendations
There are significant differences between AI chips and CPUs that matter for effective implementation and enforcement of the controls. BIS should take these into consideration if it chooses not to carve out AI-capable CPUs from the current export control regime.
CPUs are less reliant than AI chips on high-bandwidth memory (HBM). As described in our previous blog post, to help ensure that foundries are not illegally fabricating a controlled chip, they are required to screen inbound design files for HBM and more than 50 billion transistors. If the foundry identifies both of these features, they have a duty to investigate further. Unlike AI chips, however, very few CPUs incorporate HBM, making this red-flag guidance far less effective for those chips.
Additionally, the performance metrics reported for AI chips are not typically reported for CPUs. The control threshold that BIS set for AI chips in part relies on “TOPS”—a performance metric commonly reported in specification documents for those chips. CPU documentation, however, rarely specifies the chip’s TOPS. To calculate TOPS for a CPU, companies and compliance professionals will need to make subjective calls that BIS has not yet addressed; for example, whether to use the CPU’s base clock or boost clock. BIS should consider providing a standard for CPUs that helps avoid confusion and reduce the burden on industry. A red flag for AI-capable CPUs and clear guidance on how to calculate TOPS would help semiconductor foundries (e.g., TSMC and Samsung) screen out Chinese companies attempting to skirt the rules to access their cutting-edge fabrication capacity.
Lastly, CPUs are more reliant on licensed intellectual property (IP) than AI chips. Most AI chips are designed with a custom instruction set architecture (ISA), which is a technical specification that underlies every processor and describes how software will control the processor’s hardware. CPUs, however, almost exclusively rely on IP from Intel, AMD, Arm, or a RISC-V IP vendor. If BIS chooses not to carve out CPUs from the controls, it should also ensure that the controllable inputs to CPU development are also restricted so that exports of those inputs don’t undermine the controls; this could include technology in the form of ISA licenses and core IP licenses.
Appendix: Methodology for Calculating Total Processing Performance (TPP) for CPUs
In some cases, CPU designers directly report the theoretical maximum tera operations per second (TOPS) that the chips are capable of performing. This is the case for Tachyum’s Prodigy series, Tesla’s D1 chip, and NVIDIA’s Grace CPU Superchip. For these chips, Total Processing Performance (TPP) is calculated as TOPS multiplied by the bit length (e.g., 8-bit for INT8, 16-bit for FP16).
When the designer did not explicitly report TOPS—which was the case for most CPUs in our dataset—we calculated it by multiplying three variables:
- Number of operations executed per core per cycle (for a given bit length).
- Number of CPU cores.
- Number of cycles per second (GHz, with “all core boost” where applicable).10
This calculation yields giga operations per second (GOPS), which we divide by 1,000 to convert to TOPS. This calculated value is the maximum theoretical performance for a CPU, measured by the number of operations a CPU’s execution units are capable of decoding and issuing per cycle. It assumes the chip is properly cooled, that all data is in registers, that memory bandwidth is not a bottleneck, and that all operations are independent, each of which is not easy to achieve.11 In reality, operational performance will most likely fall below the theoretical maximum. However, these upper-bound assumptions are consistent with the AI chip export control thresholds, which are calculated based on a chip’s maximum theoretical performance.12
Table 2: Intel’s Vector and Matrix Extensions13
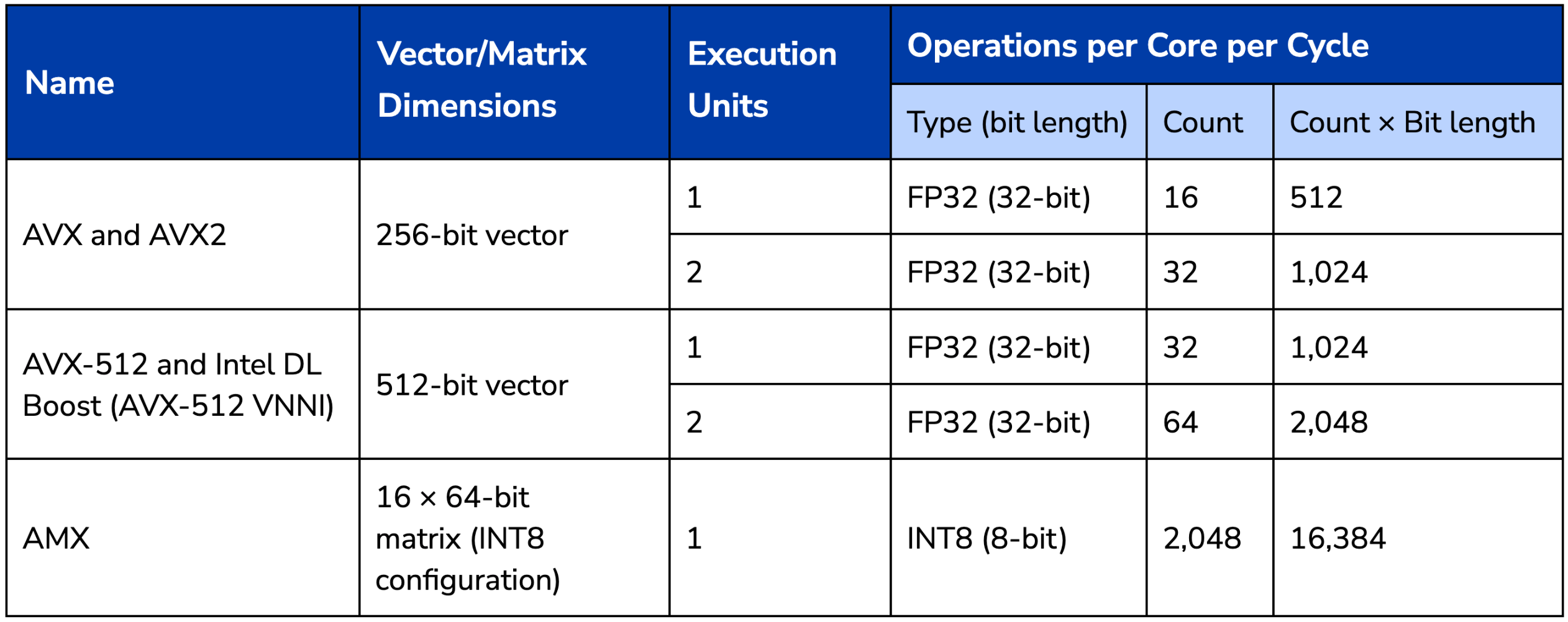
Source: CSET analysis.
– –
In addition to their work for CSET, Jacob Feldgoise and Hanna Dohmen consult for Covington & Burling LLP on semiconductor policy issues.
- For a comprehensive explanation of license requirements for “NAC-eligible” and “regular license” chips, please see Table 2 in our previous blog post.
- For 3A991.p—an Export Control Classification Number (ECCN) which controls a much broader swath of lower-performance chips to achieve anti-terrorism objectives—BIS specifically mentions CPUs.
- We define an “AI chip” product (also known as an AI integrated circuit product) as any of the following devices, if it accelerates machine learning training or inference workloads: intellectual property for a processor core (i.e., core IP), a chip subsystem (e.g., a neural processing unit), a chip, or a chip assembly (i.e., one or more AI chips on a circuit board). To accelerate AI workloads, an AI chip relies on one or more of the following processor types: graphics processing unit (GPU), central processing unit (CPU), field-programmable gate array (FPGA), or an application-specific integrated circuit (ASIC) (e.g., tensor processing unit, vector processing unit, or deep learning accelerator). Alongside the key processor element, which is executing the greatest number of AI operations per second, an AI chip may integrate multiple other processor elements on chip (system-on-chip, SoC), in package (system-in-package, SiP), or on a circuit board; we include these various types of systems in our dataset and label them accordingly.
- We prioritized validating products with a TPP greater than or equal to 1,600.
- Intel’s 5th-generation Xeon processors feature the Advanced Matrix Extension (AMX). Tachyum’s custom instruction set and corresponding microarchitecture includes a large matrix processor in each CPU core. These mechanisms increase the number of operations a CPU is capable of performing per second.
- To the authors’ knowledge, CPUs are being primarily used to conduct inference on existing AI models, not to train new ones.
- 5th-generation Intel Xeon Processors: https://perma.cc/E5RY-QLUF; Tachyum Prodigy: https://perma.cc/SGQ6-HS47.
- Nvidia used these methods to create its A800, H800, H20, L20, L2, and GeForce RTX 4090D chips. Intel did the same to release China-specific versions of its Gaudi 2, Gaudi 3, and Intel Data Center GPU Max chips.
- Note: this is for all of Intel, not just their Xeon Scalable datacenter business.
- CPUs can be overclocked above “all core boost” levels, but for the purposes of export controls, we use the advertised clock speed for each product. Specifically, we use the “all core boost” clock where available and the base clock in all other cases.
- Intel introduced a series of Xeon CPUs with high-bandwidth memory (HBM) to help reduce memory bandwidth constraints: https://perma.cc/32LR-B9B4.
- Technical note 2 to 3A090 says that “the rate of ‘MacTOPS’ is to be calculated at its maximum value theoretically possible.”
- Execution Units: Whether an Intel CPU core has one or two vector execution units varies product by product. For 3rd, 4th, and 5th-generation Intel Scalable Xeon processors, every chip has two AVX-512 FMA units except for “Bronze” category chips which only have one.
Operations per Core per Cycle – Type: For each extension, the listed data type is not the only option. We chose a type that maximized TPP. When there was a tie, we picked FP32 for consistency.
AVX: Intel Advanced Vector Extensions (AVX). See: https://perma.cc/5YVR-YG8M
AVX2: Intel Advanced Vector Extensions (AVX) 2.0. See: https://perma.cc/V3DW-53U5
AVX-512: Intel Advanced Vector Extensions (AVX) 512 Vector Neural Network Instructions (VNNI). AVX-512 VNNI is branded as Intel Deep Learning (DL) Boost. This instruction extension added support for “8- and 16-bit multiply-add instructions” to the AVX-512 instruction set family. See: https://perma.cc/JS63-YNZH, https://perma.cc/YV3G-Y339, https://perma.cc/DJJ8-C644
AMX: Intel Advanced Matrix Extensions (AMX). See: https://perma.cc/JS63-YNZH, https://perma.cc/FD6P-SYW8.