
AGORA’s user interface is designed for quick sorting and browsing. Find specific documents with a keyword search, or look for docs from different jurisdictions, time periods, or curated collections, such as Chinese law and policy or AI-focused documents from federal agencies. You can also browse AGORA’s original thematic taxonomy — for example, pinpointing documents that address AI bias, discuss evaluation requirements, or focus on AI in specific application areas like medicine or military and public safety.
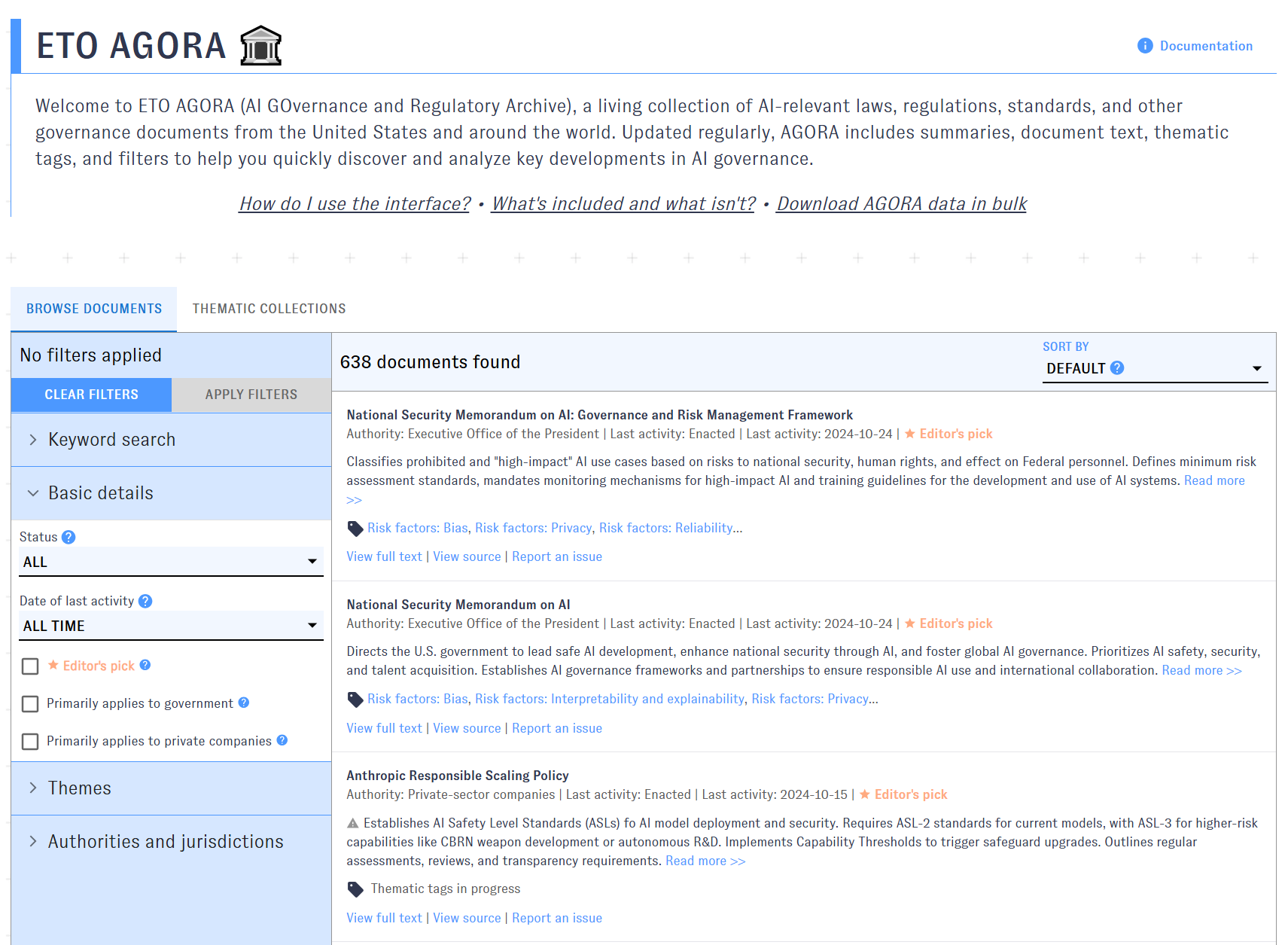
AGORA is built on an open-access dataset with full text and original metadata for every document. Our team of analysts continually compiles, screens, and annotates the latest from U.S. and official sources, using a well-documented methodology to build a systematic and transparent collection of AI law and policy.
For more details, visit ETO’s documentation for the AGORA user interface and the underlying dataset. As always, feel free to contact the ETO team with any questions.