Summary
Claims of “emergent capabilities” in large language models (LLMs) have been discussed by journalists, researchers, and even members of Congress. But these conversations have often been hampered by confusion about what exactly the term means and what it implies.
The idea of “emergence” comes from the study of complex systems. It describes systems that cannot be explained simply by looking at their parts, such as complex social networks. The field of deep learning, including LLMs, inherently involves emergence, since the internal properties of neural networks are difficult to predict simply by looking at their millions or billions of individual parameters.
A related—but distinct—definition of emergence has become common in the context of LLMs. According to this definition, emergence refers to the capabilities of LLMs that appear suddenly and unpredictably as model size, computational power, and training data scale up. Researchers have found many examples of such “emergent capabilities.” The topic has garnered attention because of the potential for the unpredictable emergence of risky capabilities (e.g., effective autonomous hacking) in the future. It has also been exaggerated in the popular press.
Some researchers dispute that LLMs exhibit sudden and unpredictable changes in their capabilities as they increase in scale. They have devised alternative metrics to measure the same capabilities that show smooth increases with scale and could potentially help predict capability increases into the future. However, devising such metrics is often not straightforward, especially for complex tasks, making it unclear how reliable this approach will be for making predictions.
While there are some methods for estimating the capabilities of LLMs before they are trained—and these will hopefully improve so that researchers can predict even seemingly sudden jumps in capabilities—researcher and policymaker ability to predict the future of LLMs is far from assured. Previous attempts to predict capabilities in advance of further scaling have had decidedly mixed results. Even long after LLMs are initially trained, researchers can discover simple techniques that improve their capabilities dramatically on certain tasks. Furthermore, performance on benchmarks can only tell policymakers so much about the usefulness or risk of LLMs in the real world. More research is therefore needed to measure and predict capabilities of LLMs so policymakers can be better prepared to anticipate and mitigate their risks.
What is Emergence?
“Emergence” is a term used in many different fields, but it is most closely associated with the field of complex systems. The phrase “the whole is more than the sum of its parts,” is attributed to Aristotle, but the observation was surely first made long before that. If a system exhibits emergence, it is difficult to determine how the whole system will behave simply by observing its parts.
The behavior of a whole ant colony emerges from that of the individual ants; market prices emerge from many individual interactions in an economy; bureaucracies seem to take on a life of their own separate from any individual member. In all cases, it would be difficult to grasp the behavior of the whole simply by looking at each individual part.1 The human brain, which produces consciousness and thought from a poorly-understood web of interconnected neurons, is another oft-cited example.
Examples of emergence are so common that the term often has limited usefulness. In fact, it is hard to think of a system that doesn’t exhibit emergence. In describing emergence, the philosopher Mark Bedau wrote that “[i]t is not a special, intrinsically interesting property; rather, it is widespread, the rule rather than the exception.”
Yet for many designed creations, emergence is more limited. Because cars are designed by humans, they can more or less be explained by studying their parts. If a part fails, it can be replaced with an identical one (try doing that with a bureaucracy). Even if you yourself do not know how the parts of a car combine to form a working vehicle, there are many people who do.
Much of computer science has been concerned with building systems that are modular, meaning that, like a car, their parts can be easily modified on their own to produce predictable effects on the whole. Many traditional computing algorithms rely on dividing a problem into its parts, solving each part individually, and then combining the solutions for an answer. In computer science, emergence is often associated with bugs or errors rather than desirable results.
Emergence in Deep Learning
In contrast to most of computer science, emergence is treated differently in deep learning, including LLMs. In deep learning, emergent behavior is not only tolerated, it is necessary.
Deep neural networks begin as nothing more than a mathematical function of randomly chosen numbers, and there is no manual process of adjusting those numbers. Programming LLMs does not involve manually specifying facts like “apples grow on trees” or “the verb ‘bring’ requires an object,” even though trained LLMs do learn these things.
LLMs, and neural networks more generally, are instead trained through a process called backpropagation, as described in an earlier CSET explainer. To summarize, the initially-random numbers (called parameters) are adjusted so that the neural network becomes more likely to convert inputs to outputs in the desired way.
Programmers specify the general algorithm used to learn from data, not how the neural network should deliver a desired result. At the end of training, the model’s parameters still appear as billions or trillions of random-seeming numbers. But when assembled together in the right way, the parameters of an LLM trained to predict the next word of internet text may be able to write stories, do some kinds of math problems, and generate computer programs. The specifics of what a new model can do are then “discovered, not designed.“
Emergence is therefore the rule, not the exception, in deep learning. Every ability and internal property that a neural network attains is emergent; only the very simple structure of the neural network and its training algorithm are designed. While this may be unusual for computer science, it is not for the natural systems from which neural networks derive their name.
Emergence As Sudden Scaling in Large Language Models
More recently, people have begun to use the term “emergence” differently in the context of LLMs to describe abilities that arise suddenly and unpredictably as models scale.
LLM performance isn’t totally unpredictable. A branch of research known as scaling laws focuses on how well language models of different scales predict the next word. As LLMs are trained using more compute, data, and parameters, the models generally get better at predicting the text they are trained on. But by how much? Research into scaling laws has shown that ability to predict internet text improves smoothly and predictably as models scale. And since model performance at all kinds of tasks correlates with ability to predict internet text, models generally get better at many tasks as they increase in scale.
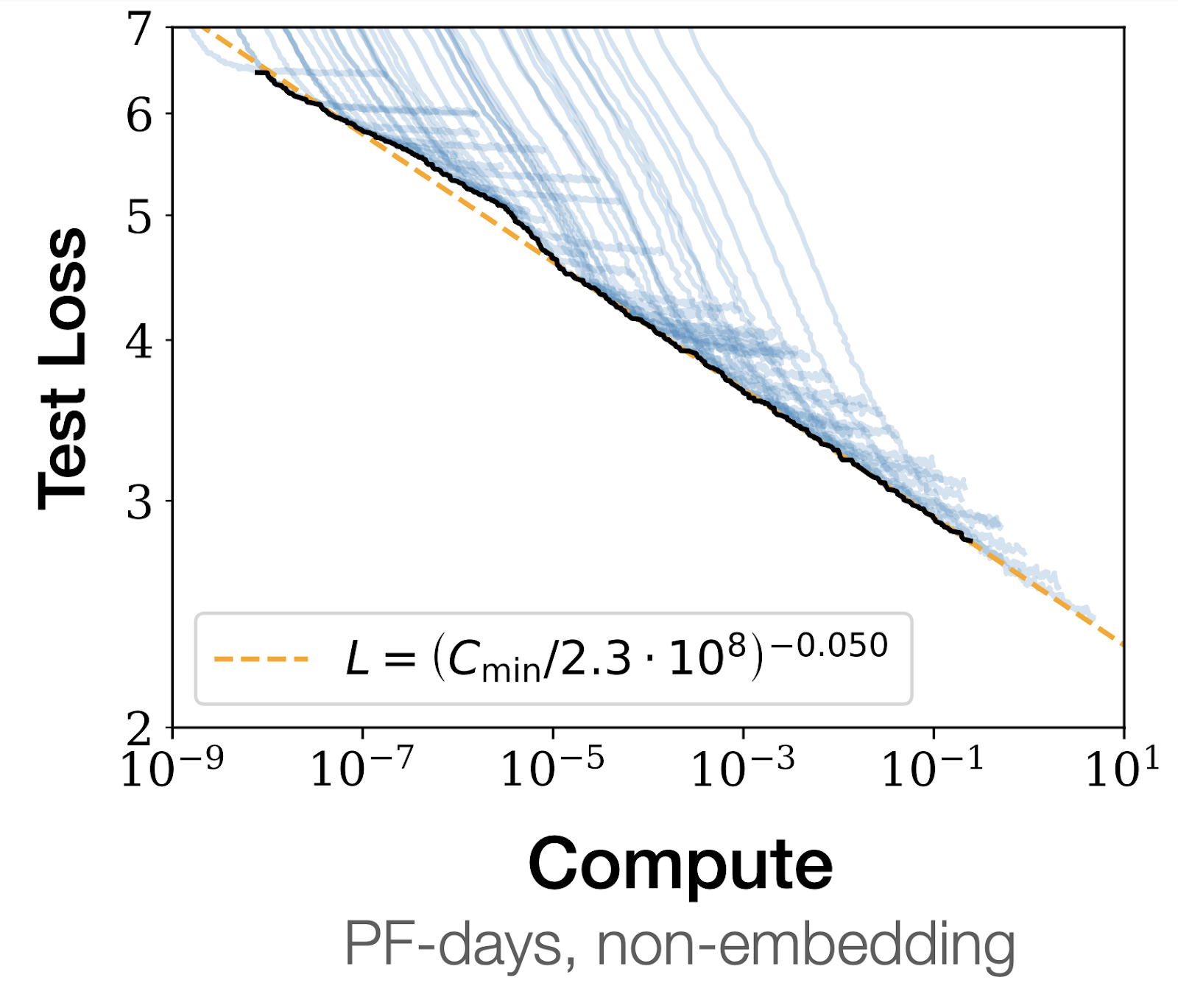
A graph from one of the first papers applying scaling laws to transformer language models. As more compute is used to scale models, the “loss,” a measure of the model’s ability to predict unseen internet text, decreases smoothly and predictably (the exact scaling trend depicted here has since been superseded, but the general idea still holds).
While perplexity changes smoothly as models scale up, performance on individual tasks is more choppy. One example that has been often cited is three-digit addition. LLMs could not perform three digit addition very well until they reached a certain scale, when performance suddenly jumped. (The next section describes how others have disputed this characterization.)
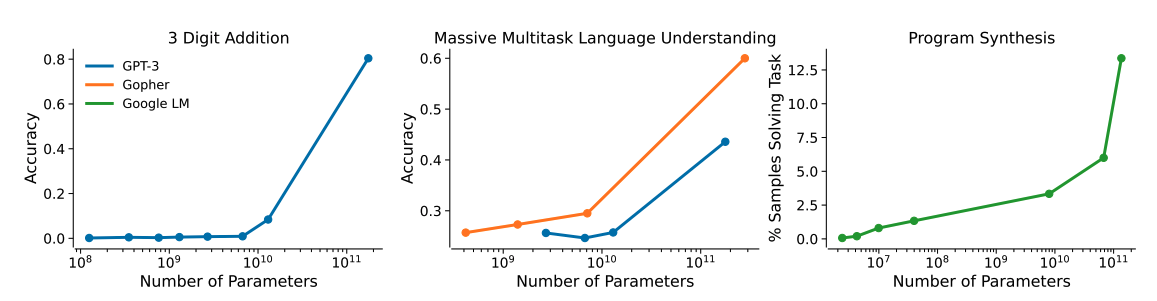
Graphs of several metrics that improve suddenly and unpredictably as models increase in size (source).
Researchers began to use the term “emergence” to describe these unexpected jumps.2 This usage is not quite the same as the original usage in complex systems theory, but “emergence” is the term that has stuck. Emergence was considered important in part because “we are better able to make models safe when we know what capabilities they possess,” and capabilities that arose unpredictably might be more difficult to identify. In the future, emergence implies that genuinely dangerous capabilities could arise unpredictably, making them harder to handle. For example, if models suddenly became able to identify and exploit critical software vulnerabilities at a certain scale, this would be harder to handle than if improvements had come more predictably.
In 2022, researchers (mainly at Google at the time) published Emergent Abilities of Large Language Models (hereafter Emergent Abilities), which has become the most-cited paper about this phenomenon. They wrote that “an ability is emergent if it is not present in smaller models but is present in larger models.” The paper referenced a blog post from UC Berkeley professor Jacob Steinhardt, who defined “emergence” as “qualitative changes that arise from quantitative increases in scale.” Steinhardt wrote that he had been inspired by the 1972 physics paper More is Different.
The definition given in Emergent Abilities was not complete. First, the definition makes no direct mention of suddenness, but the authors are clear that they don’t consider abilities that arise gradually with scale as emergent. Second, the definition makes no mention of unpredictability, though the paper claims elsewhere that “emergent abilities cannot be predicted simply by extrapolating the performance of smaller models.” The elements of suddenness and unpredictability are generally considered to be important to the paper’s claims.
Is Emergence A Mirage?
After Emergent Abilities, the concept of “emergence” began getting much more attention, with the popular press at times exaggerating it. For example, a 60 Minutes voiceover declared “some AI systems are teaching themselves skills that they weren’t expected to have.” (The claim that LLMs “teach themselves” was never part of any scientific definition of emergence.) In 2023, researchers at Stanford published a paper titled Are Emergent Abilities of Large Language Models a Mirage? (hereafter Mirage) claiming that emergence is merely a “mirage” that appears because of “the researcher’s choice of metric rather than due to fundamental changes in model behavior with scale.”
Mirage noted that many common metrics, including many used in Emergent Abilities, measure only the black-and-white question of whether a system has succeeded at the task or not. These metrics do not distinguish between systems that can mostly solve the task and those that cannot solve the task at all. In other words, they don’t give partial credit. Mirage devised smooth metrics that did give partial credit for some of the same tasks and found there were no sudden changes with these metrics. For example, even though there was a sharp improvement in performance at three-digit addition, the model’s ability to predict each individual digit increased smoothly. With this metric, the researchers could directly predict the sudden changes in the original three-digit metric.3
It is important to note that many of the metrics that showed emergence are more practically important than those that did not. A language model that can almost perform a task is not much more useful than one that can’t perform it at all, so the “all or nothing” metric may be more important. Mirage did not dispute this: it simply claimed that different, continuous metrics could be used to directly predict the discontinuous (and perhaps more important) metrics.
Mirage made a splash in the research community and even resulted in the House Science Committee writing that it had caused Emergent Abilities to be “debunked by rigorous statistical analysis.” However, the results in Mirage were not unforeseen by the authors of Emergent Abilities, who had written in the original paper that discontinuous metrics “may disguise compounding incremental improvements as emergence.”4
Finally, the alternative metrics found in Mirage were only developed after capability jumps were first discovered. A significant unresolved question is whether performance can be predicted in advance, rather than only for models at scales that have already been tested.
Can We Predict LLM Capabilities?
As debates over emergence continue, LLMs are getting better. A central question for policymakers is just how much better LLMs will get and how quickly they will get there. Some of these questions are those of economics: what scale will LLM companies train models at next year? But some of them are scientific: assuming that we know the scale that a model is trained at, can we predict what capabilities it will have? If we cannot, we may be surprised by hazardous capabilities.
Mirage showed that capabilities that appear to emerge suddenly are often more predictable if they can be decomposed into metrics that improve continuously. But doing this decomposition ahead of time is challenging. Consider an experiment conducted by the RAND Corporation, where different groups of researchers (some with access to an LLM, and some without) spent hundreds of hours devising and scoring biological weapons plans to determine whether current LLMs were helpful aids for developing plans for bioterrorism (they don’t seem to be). Are there easy to measure, continuous metrics that would allow us to predict exactly at what scale experiments might show that future LLMs are significantly helpful for devising these kinds of plans? Perhaps, but developing them would not be straightforward.
Once a model has been trained, it becomes easier to assess its capabilities, but even then, there are several gaps. First, present-day evaluations may not be sufficient for future, more capable AI systems. For example, it took almost a year after the release of GPT-4 to develop and execute the trials described above measuring the (lack of) usefulness of GPT-4 for assisting with the creation of biological weapons—and even this study had limitations. Second, simple techniques developed after training may dramatically improve LLM abilities. For example, chain-of-thought prompting, where a model is asked to “think step by step,” can make models much better at mathematical tasks without any further training. Evaluations that don’t account for such changes will likely understate models’ capabilities. Finally, evaluations are generally only able to show the presence of a capability, not its absence. For example, just because a red teamer cannot manually find a prompt to “jailbreak” a model does not mean that such prompts cannot be found algorithmically. In short, it is difficult to assess the capabilities of a model even after it is trained.
There have been a few efforts to explicitly predict the capabilities of LLMs into the future. For example, UC Berkeley Professor Jacob Steinhardt has been running real-money forecasting competitions for several years. When asked to make predictions in 2021, researchers dramatically underestimated what the performance of LLMs would be on certain tasks by 2022. The predictions they made in 2022 were much more accurate for 2023, but future performance remains to be seen.
Most predictions of progress in LLMs, and the debate around emergent capabilities, has been around specific benchmarks. But even if we could predict benchmark performance, that may not be sufficient. What researchers and policymakers care about is the effect models have on the real world, including the real-world benefits and risks of a system. Predicting how results on benchmarks translate into tangible impact in the world may be even more difficult than predicting the benchmark results themselves. Just as benchmark results could catch us by surprise, so might real-world impact.
Takeaways
LLMs sometimes possess abilities that their developers did not predict. Developers of LLMs do not program them explicitly and only test for their capabilities after they have already been trained. It is thus not very surprising that unexpected developments sometimes occur. These developments are neither magical nor inexplicable: we just have limited ability to predict them.
There has been progress in predicting what abilities LLMs will possess. Research in scaling laws, as well as the development of continuous metrics that can help predict more discontinuous metrics (like those found in Mirage), have improved our ability to predict what future LLMs will be able to do.
Serious gaps remain in our ability to predict the future of LLMs. New training techniques, datasets, and prompting techniques keep researchers on their toes when trying to predict how quickly LLMs will evolve. Even if continuous metrics can theoretically be devised that help us predict more discontinuous metrics, it may be difficult to devise them. Lastly, we can’t predict capabilities that we didn’t think to measure in the first place.
Unpredictable advances pose more risk. Unpredictable and sudden jumps in capabilities, especially dangerous capabilities, create a risk that models will pose threats without time for adequate mitigation measures.
More research is needed in predicting and measuring LLMs capabilities. Better prediction and measurement would allow us to know how much risk LLMs really pose, and when such risks could arise in the future. Significantly more research is needed in this area, including the prediction of real-world impact, before confident predictions and even measurements can be made.
- Importantly, this does not necessarily mean that it is impossible to predict the whole from the parts, simply that it is very difficult. While some philosophers have proposed definitions of emergence that do imply impossibility (for example, “strong emergence”), those definitions certainly do not apply to deep learning and are not a consideration here.
- Papers with this usage include Bommasani et al. (2021), Steinhardt (2021), Hendrycks et al. (2021), Steinhardt (2022), Ganguli et al. (2022), and finally Wei et al. (2022).
- Precisely, the metric used was token edit distance, which is the number of tokens (in most cases, digits) that would need to be added, deleted, or edited from the model’s answer in order to obtain the correct answer.
- Note again Emergent Abilities’ formal definition of emergence: “an ability is emergent if it is not present in smaller models but is present in larger models.” Abilities present in larger models but not smaller ones could of course result from “compounding incremental improvements,” in much the same way as one might say that basketball abilities present in NBA players and not their 5 year old past selves result from compounding incremental improvements. And yet, this section of Emergent Abilities rejects the idea that this would be “emergence.”