Introduction
The AI workforce is an unavoidable subject in any comprehensive discussion about AI strategy. Governments are designing strategies to grow it, companies are competing for it, and researchers are using it to gauge national capacity. Yet despite the central role of this workforce in AI competition, the terms “AI workforce” or “AI job” can mean very different things in different contexts. Definitions vary across organizations, and prevalent measurement approaches can either include overly broad sets of AI-adjacent roles or miss emerging technical work that does not fit cleanly into existing occupational buckets.
This blog introduces CSET’s new approach to defining the AI workforce: we define AI development jobs as roles that directly contribute to technical development of AI systems. Our new methodology provides a way to distinguish AI development jobs from broader AI-adjacent work, and to measure demand for those roles using job postings data.
Why Definitions Matter
Precise AI workforce data is critical for developing effective policy. Workforce data helps determine what we think is scarce, what we train for, and what we need to try to import. As of now, official labor statistics do not neatly capture AI work. Without a clear taxonomy, basic questions about who is developing AI (and how) remain hard to answer.
Clarity is especially important right now because the term “AI” is increasingly used as a catch-all. The most prevalent methodologies (described below), those that use skills-based counts, are particularly susceptible to this because they blur together three different labor markets: (1) people building AI systems, (2) people adopting AI tools in other roles, and (3) workers whose tasks are exposed to AI-enabled change. When these distinct groups are aggregated under a single “AI workforce” label, it becomes difficult to diagnose technical talent shortages, assess development capacity, or design targeted workforce interventions. A more precise definition helps separate diffusion from development and ensures that policy discussions are grounded in the appropriate segment of the labor market.
Distinguishing between these groups does not diminish the importance of AI adoption or exposure. Rather, it clarifies which workforce we are attempting to measure. If the goal is to understand national AI development capacity, then the metric should reflect the technical workforce responsible for designing, training, and deploying AI systems and not the much broader universe of workers who interact with AI tools.
Prevailing Definitions to Date
Any effort to define the AI workforce must resolve two related questions: a conceptual one and an operational one.
- Conceptually: What do we mean by an “AI job” in the first place?
- Operationally: How do we determine whether a specific role should be counted?
The first asks what kinds of roles should count as an “AI job” at all. The second asks what observable signal, such as an occupational category, job title, or skill requirement, will be used to identify those roles in practice.
In principle, these questions are distinct. Researchers can first decide what they want “AI job” to mean and then choose a methodology to implement that definition. In practice, however, the relationship is often less clean. Some studies begin with a substantive definition and then operationalize it through occupations or skills, while others effectively let the classification rule define the category itself, for example, by treating any role with a designated AI skill as an AI job.
Much of the existing research relies on one of two broad methodological approaches. The first is an occupation-based approach, which identifies the AI workforce by selecting specific occupations or closely related job categories and treating workers in those roles as AI workers. The second is a skills-based approach, which identifies AI workers based on the presence of AI-related skills in job descriptions or worker profiles, regardless of formal occupation.
Occupation- and skills-based methodologies provide structured, replicable ways to measure the AI workforce, and they underpin much of the existing literature. Yet the choice of framework, together with the underlying conception of what qualifies as an “AI job,” meaningfully shapes the resulting estimate. Different approaches capture different types of work, include different groups of workers, and lend themselves to different forms of analysis. Assessing their respective strengths and weaknesses helps clarify the value of CSET’s new, refined definition.
Occupation-Based Approach
Occupation-based approaches define the AI workforce by selecting specific occupational codes, typically within federal classification systems such as the Standard Occupational Classification (SOC), and treating workers in those occupations as AI workers. CSET’s earlier work on the U.S. AI workforce followed this model, identifying occupations involved in the AI development process and linking them to Census and Bureau of Labor Statistics data to estimate overall supply.
This approach offers several important strengths. Because it aligns cleanly with federal datasets, it enables rich supply-side analysis of education, demographics, wages, and geography. The results are legible to policymakers accustomed to thinking in occupational terms, and the relative stability of occupational codes allows for longitudinal trend analysis. Most fundamentally, occupation-based methods provide a comprehensive view of the total potential supply of AI-relevant talent.
At the same time, the approach has structural limitations. Occupational taxonomies lag technological change and aggregate diverse roles under a single label. As a result, this method can both overcount (by including entire occupations in which only a subset meaningfully engage in AI development) and undercount (by excluding AI development activity embedded within “non-AI” occupations). Because it measures potential supply rather than active engagement, it tends to generate large aggregate estimates that require careful interpretation and substantial caveats. In short, it provides a valuable macro-level picture but with limited granularity about who is actually developing AI systems today.
Skills-Based Approach
Skills-based approaches define the AI workforce based on the presence of AI-related skills in job postings or worker profiles. Rather than starting with occupational codes, these methods begin with a predefined list of AI skills, often drawn from the Lightcast Skills Taxonomy, and classify a role as “AI” if the required skills list references one or more of those skills. This framework using Lightcast’s taxonomy has become the dominant approach in recent years and underpins analyses by Stanford HAI, Brookings, the Organisation for Economic Co-operation and Development (OECD), and other researchers.
The appeal of this approach lies in its responsiveness, specificity, and straightforward implementation. Because it usually draws skills directly from job postings, it is highly sensitive to real-time change and can capture emerging tools, platforms, and techniques almost immediately. It can also track the diffusion of AI skills across sectors and occupations, rather than confining analysis to traditional technical roles. It provides a strong demand-side signal, reflecting what employers say they need now, including wage premiums and growth rates.
At the same time, skills-based approaches face important limitations. The approach can be volatile and sensitive to hype cycles; sudden spikes in mentions (e.g., generative AI) may reflect short-term enthusiasm rather than sustained structural demand. Their added specificity also creates a trade-off. While skills-based methods can identify AI-relevant work more precisely than occupation-based approaches, they can be harder to link to other datasets at the same level of granularity, which can limit supply-side analysis of the existing workforce.
A related limitation of skills-based approaches is their reliance on expansive lists of AI skills, where the presence of any single skill in a job posting is sufficient to classify the role as an AI job. This approach likely overstates the number of postings that reflect core AI development work, as it captures roles that may only use AI tools incidentally, reference AI in peripheral job functions, or participate in AI-related work without being directly responsible for system design, development, or deployment. As a result, these methods can blur distinctions between workers whose core expertise lies in AI development and those whose engagement with AI is more peripheral.
It is also important to distinguish the limitations of the skills-based approach itself from the limitations of the data often used to implement it. Datasets of aggregated job postings are a popular source of labor market analysis and are widely used in both skills-based and occupation-based analysis. This makes the strengths and weaknesses of posting data especially important for interpreting estimates of employer demand, and for any broader workforce claims built on those estimates. Job postings are an imperfect proxy for actual work: not all jobs are posted, postings for “ghost jobs” are not meant to be filled, and postings may reflect HR templates, signaling behavior, or aspirational requirements rather than day-to-day responsibilities. Vendor opacity also introduces classification risk, as skill taxonomies, parsing methods, and error rates are often proprietary or not fully disclosed.
CSET’s New Definition: AI Development Jobs
Our new methodology narrows the focus of CSET’s previous definition. We now define AI development jobs as roles that directly contribute to technical development of AI systems. Our wording was carefully constructed to draw a clear boundary around roles that demand AI-specific knowledge, skills, and abilities (KSAs), excluding positions for which AI involvement is incidental or tangential. This scoping captures positions involved in the design and development of AI systems, but only if the role actually requires AI-related expertise.
To classify whether a role counts as AI development work, we used the following decision matrix:
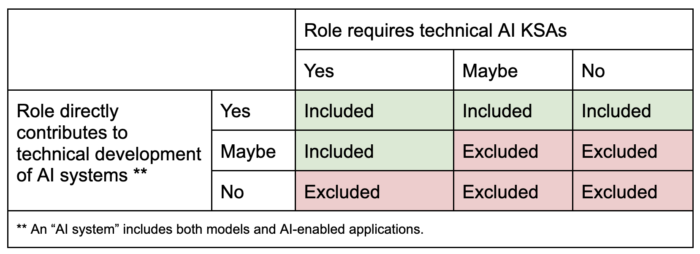
This definition draws a clear line: a project manager on a technical AI development team counts, but a cloud database administrator does not. One directly contributes to building the AI system; the other provides general infrastructure support and does not require AI-specific KSAs.
Using this framework, we constructed a job postings classifier to identify such postings at scale. Built on a dataset of 448 million job postings from Lightcast between 2010 to 2024, the model incorporates information from job titles, job duties and responsibilities sections, and the specialized KSAs listed. Our resulting model achieved 91.67 percent accuracy in test data.
This approach combines the strengths of prior methods while mitigating some of their limitations. Similar to recent skills-based approaches mentioned previously, it leverages real-time job postings data to capture employer demand as it evolves. But unlike expansive skill-list approaches, it does not classify a role as “AI” based on the incidental presence of specific keywords. Instead, it evaluates whether a position substantively requires AI-specific technical knowledge and contributes directly to system development. At the same time, by clearly defining the boundary of AI development work, it avoids the overcounting of occupation-based methods that include entire job categories regardless of actual task content.
The result is a narrower and more precise measure of demand for the core AI development workforce. For policymakers and researchers seeking to understand AI capacity, this sharper definition distinguishes between broad AI diffusion and the technical talent responsible for building and deploying AI systems themselves.
What’s Next?
A more precise definition is only useful if it leads to more actionable evidence. The next phase of this work will use this framework to generate an initial snapshot of AI development jobs and examine where these roles are appearing, what skills they require, and how they are changing over time. We will build on that demand-side foundation by connecting it to worker profile data to develop supply-side indicators and better inform workforce policy.