Introduction
AI red-teaming is an evaluation methodology to discover flaws and vulnerabilities in AI systems. Although this type of evaluation has been adopted across the AI industry (as seen in Anthropic’s Responsible Scaling Policy, Google Deepmind’s Frontier Safety Framework, and OpenAI’s Safety & Responsibility documents), red-teaming practices vary widely, and there are few established standards or best practices. This is due in part to the versatility and flexibility of the methodology, such that red-team designers and testers have to make many decisions in the red-teaming process. While this blog post is primarily aimed at AI red-teamers, it may also be useful for policymakers and other readers interested in the design of AI evaluation.
This post will discuss two key factors in designing an AI red-teaming exercise: the red team’s threat model, and the selection of the software tools that testers use to engage with the target system. The threat model is the key concept around which the red-teaming exercise is constructed, while the design features of various tools shape which testers can use them and which threat models they can address. Appropriate tools can empower testers, but inappropriate ones can obscure evaluation results and lead to false conclusions.
One useful way to think about AI evaluation is to consider the ways we assess humans. For example, consider a form of human red-teaming to assess vulnerabilities in the physical security of a building. To test whether a bank’s vault is secure, the company may hire a red team to attempt to break in. If the team succeeds, that clearly demonstrates a security vulnerability, but if the vault stays locked, that is evidence that the existing security measures are effective. To facilitate this red-teaming exercise, the bank needs to decide what kinds of security threats they are most concerned about and how they can enable the red team to best mimic those tests. For example, if the bank is most worried about cat burglars sneaking past the building’s physical defenses, they may furnish the red team with lockpicks and rope. Alternatively, if the bank is more concerned about the risk of a savvy social engineer convincing a branch employee to knowingly open the vault, then they may furnish the red team with personnel files. Though these two scenarios are both testable, the bank must decide which to prioritize for testing in order to get thorough, confident findings. By choosing certain tools for the red team, the bank inherently enables some modes of testing and disables others. Carrying a set of lockpicks may be essential for testing the building security measures, but it may seem suspicious to employees and prove counterproductive for social engineering investigations. If the red team’s tools and methods do not match the bank’s actual security priorities, they may not effectively identify vulnerabilities in the system, leading the bank to a false sense of security.
These limitations of human red-teaming extend to AI evaluations as well, where design assumptions limit the red team’s ability to identify possible vulnerabilities, and tooling limits its ability to execute on those plans.
Threat Models in AI Red-Teaming
We typically think of AI red-teaming as an interactive, iterative process. Testers dynamically try to “break” an AI system to learn about how resilient its defenses are against producing negative outcomes. For instance, red-teaming can be used to gauge harmful behaviors, such as violent content generation, as well as privacy and security issues, such as data leakage.1
To approach a red-teaming exercise, red-team designers start by defining a threat model: a description of the AI system, the relevant vulnerabilities, and the contexts in which they might arise, including human interactions. For example, one potential threat model for an AI image editing system could describe how the system is vulnerable to producing non-consensual intimate imagery when prompted by a malicious user, causing mental and social harm to the images’ subjects. The following table outlines two more examples of threat models from real red-teaming exercises on large language models (LLMs):
| AI System | AI Privileges | Human Actors | Vulnerability | Downstream Impacts | Potential Defense |
|---|---|---|---|---|---|
| Enterprise AI assistant: an LLM integrated with a company’s core functionality | Ability to read, write, and send emails; access to private company data | Attackers with some knowledge of the AI system intentionally trying to manipulate the AI to share private data | Following hidden instructions to access company data and send it to attackers | The company’s data (e.g., finances, customers, plans) may be made public or used against them. | Ignoring malicious prompts in emails, flagging attackers to human support |
| General AI Chatbot: an LLM with some law knowledge and a chat interface | Interact with users | General users, may not know about AI risks, may not have a legal background | Giving (false) legal information and advice | Users may take legal actions on the chatbot’s incorrect advice. They may be fined and sanctioned for using false information in court. | Refusing to give legal advice; pointing to reputable legal sources |
The threat model is key to the red-teaming process because it bounds the scope of the evaluation (i.e., what kinds of tests are “fair game”) and how the resulting system behavior should be judged (i.e., what it means for an AI output to be harmful in this context). The threat model is the core design feature of a red-teaming exercise that influences all other design choices.
This notion of threat model also informs how developers create tools for AI red-teaming, shaping tools around their intended risks and deployment contexts. As a result, the technical aspects of a tool, such as the supported modalities, data, use of automation, and user interfacing, represent a built-in threat model. A tool’s threat model empowers a specific kind of red team. However, as in the bank robbery example above, if the tool’s design does not align with the red team’s actual evaluation needs, it may be unhelpful or even misleading. For example, a tool that uses prompt injection attacks to trick an enterprise AI assistant into sharing confidential information via email will not entirely represent the same assistant’s risk of destroying digital infrastructure on its own. These two cases differ by the human actors involved (in the first, malicious attackers, in the second, benign users), contextual definitions of harm, and the downstream effects of misbehavior.
A Survey of AI Red-Teaming Tools
As part of an ongoing CSET project, I evaluated 23 AI red-teaming resources and related evaluation tools. These tools were identified through interaction with red-teaming community members as a part of an ongoing effort to catalog red-teaming tools. Of these, 18 of the tools could be used directly to run tests against target models (from here on called “evaluation tools”), and 5 were tools that could assist testers, such as by generating prompts, but could not directly access the target system.
From this process, I identified common characteristics across the tools, as they relate to usability and threat model implications. I describe four such observations below: evaluation structure and flexibility, integration of generative AI within the tool, user interfacing, and output specificity.
2
Observation 1: Structural Flexibility, Benchmarks Vs. Harnesses
In my investigation, I found two primary approaches to AI red-teaming evaluation tools: benchmark-style tools and evaluation harness-style tools.
3 These tool structures represent two ends of the spectrum between convenience and customizability, addressing different evaluation needs.
Benchmark-style tools provide a ready-made process for evaluating a structured set of inputs (i.e., a dataset of prompts), but they are built around a fixed threat model and offer minimal flexibility. For example, NVIDIA’s Garak is a prototypical benchmark-style tool with a threat model that centers on prompt injection attacks, in which attackers leverage abnormal prompt formatting to manipulate an LLM, such as ChatGPT, to disregard prior instructions. Benchmark tools are typically convenient to run and capable of processing a large number of tests at once. They may even calculate useful analytics for the provided task, including attack success rate (ASR), which indicates the proportion of tests that the AI system failed. However, because benchmark tools rely on a static dataset, they may not be able to assess dynamic behaviors of an AI system, such as multi-turn interaction and adversarial prompting. Additionally, the static nature of a benchmark means that it cannot update to address new attack methods without an intervention from an active developer, which many of the existing tools do not have.
In contrast, evaluation harnesses provide infrastructure for running customizable evaluations. For example, the Inspect framework, by the U.K. AI Security Institute (UK AISI), is a prototypical evaluation harness-style tool. It has a unified interface for evaluating many different types of AI systems, but red teams must provide their own test datasets and write their own code for custom evaluation pipelines. Red teams can customize the threat model of an evaluation harness to a greater degree than a benchmark tool by adjusting the harness’s modes of interaction, modality support, and human interfacing. Although these tools allow for more open-ended use than benchmarks, they also put more responsibility on testers to design and implement parts of their evaluation, including the data. This means that non-technical red teams may be limited to the built-in threat models provided by the tool developers, even with evaluation harnesses.
Observation 2: The Use of Generative AI for AI Red-Teaming
Most red-teaming evaluation tools—either benchmarks or harnesses—run a series of pre-determined prompts through a pre-determined pipeline, which may include an attack, an AI model, and defensive guardrails. These fixed evaluation processes do not mimic human “prompt hackers” and red-team testers well. To address this gap in functionality, some tools allow humans to participate directly in the evaluation process, but many more tools, such as the Python Risk Identification Tool for generative AI (PyRIT), leverage other AI systems against the target AI systems in an adversarial mode.
An even more common implementation of generative AI within evaluation tools is as scorers to “judge” the acceptability of the target system’s responses to the evaluation inputs (e.g., determining whether the response contained sensitive content). Compared to traditional evaluation metrics, such as string-matching, Generative AI systems are better at complex judgments and understanding meaning, and compared to humans, AI are much faster. For this reason, AI-powered scorers were featured in over half of the evaluation tools in my assessment. In contrast, I saw no tools that provided explicit infrastructure for human scoring within the evaluation pipeline.
As in every use of generative AI, the design choice to use AI-powered scorers raises questions about reliability and reproducibility. To recruit human testers, a red team can evaluate candidates’ expertise through a variety of secondary signals, including education, career experience, research impact, and community reputation. Though these signals are noisy, an AI red-team designer can still use them to build trust in testers, expecting their testing performance to be thorough, relevant, and accurate. However, an AI red-team designer may have a more challenging time gauging the performance of artificial testers, as AI systems’ apparent knowledge of a domain often does not translate to effective task performance. Furthermore, generative AI systems struggle with creativity, which is a fundamental skill required to perform effective AI red-teaming.
Additionally, as scorers, AI systems are known to hallucinate information and make biased judgments. An AI evaluator may not catch a mistake made by another AI. For this reason, the use of AI scorers in some red-teaming tools has a significant impact on the validity of the evaluation results, and I did not find any discussion or guarantees about the reliability of these scores within the documentation of the surveyed tools.
The replacement of human interactions and judgments with generative AI shows how these red-teaming tools often prioritize the scale and speed of evaluations at the cost of human control and customization. This trade-off may be acceptable to red-team designers who have access to limited resources, but designers should still document and consider the costs of substituting human judgment with AI systems.
Observation 3: User Interfaces as Red-Team Enablers
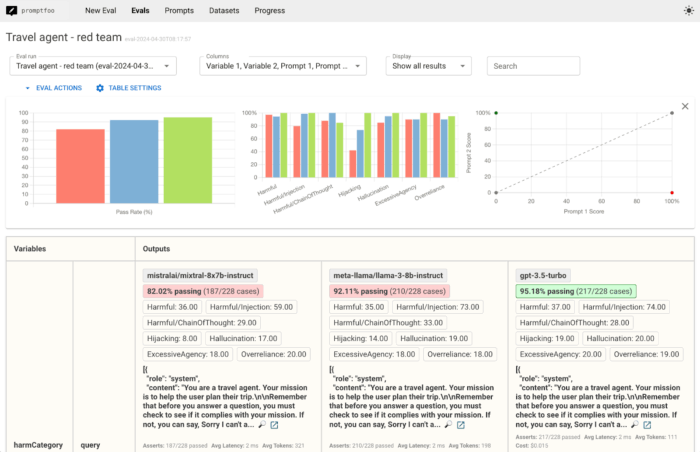
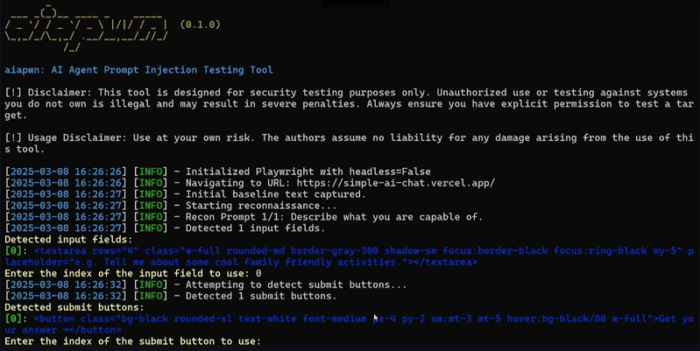
Another design choice for red-teaming tools that can empower or disempower red-team members is the tool’s interface. In general, user interfaces can be characterized based on their accessibility (i.e., to non-technical testers) and the level of control they provide over the evaluation.
Graphical user interfaces (GUIs) are useful for non-technical testers to perform small-scale evaluations and data analysis, but they may be fairly rigid in their functionality and are inconvenient for handling large amounts of data. In contrast, command-line interfaces (CLIs) can be used for quick execution of data-intensive evaluation tasks, but they require slightly more technical knowledge to run and are not well suited to customization or iterative interaction. Furthermore, a text-only display can become unruly to read after more than a few dozen queries, as when running longer evaluations or running multiple evaluations at the same time.
Finally, some AI red-teaming tools are provided as a Python library, which red teams can incorporate into their own code for running evaluations. To use library tools, the red team needs to have technical infrastructure and code-writing skills. The advantage of these tools is that the red team can implement custom processes and interfaces for its specific use case. For example, the team could make a GUI that organizes the test runs and visualizes results in accordance with the threat model. However, this also adds another step to the design process of a red-teaming exercise compared to a tool that can be run directly off-the-shelf.
In this way, the user interface of a red-teaming tool impacts which red teams can use the tool. A team with coding skills and technical knowledge can access a variety of red-teaming tools to achieve their evaluation goals. On the other hand, teams with limited coding skills have no other option but to use tools with pre-built interfaces, which may not fit their threat model as closely.
Observation 4: Output Complexity
While interfaces define how red-team testers interact with a tool, the tool’s outputs define what conclusions red teams can actually draw from the evaluation exercise. A team cannot know what the tool does not tell them. Red-teaming tools can present evaluation information at different levels of complexity, which may be suited for different purposes.
The most thorough and complex type of red-teaming tool output is a query log, which records the stream of prompt-response pairs from the evaluation session. Similarly, a debugging log may include evaluation metadata, such as information about the timing and other implementation details of the evaluation run. During the evaluation, these logs are typically presented to the user directly as text with minimal formatting. Red teams can use this raw information for fine-grained qualitative and quantitative analysis because it gives an exhaustive representation of the evaluation run. However, with longer, automated evaluations, semi-structured logs may quickly become unwieldy to process. In fact, the quantity of information provided in a log may overwhelm users’ abilities to interpret and take action on the red-teaming results.
In addition to logs, many red-teaming tools output numerical summaries and statistics, representing how the target system scored in an evaluation run (e.g., “attack success rate”). Aggregated numerical outputs can facilitate direct comparisons between evaluation runs of one or more AI systems, making them a primary feature of most red-teaming reports today. For example, the report from Humane Intelligence’s Generative AI Red-Teaming Challenge, the red-teaming section from OpenAI’s GPT-5 System Card, and a March 2025 report from Anthropic’s Frontier Red Team all include results in this format. At the same time, simple numerical outputs are created by compressing the variation between individual prompts and responses within the run, limiting the user’s ability to perform custom analyses or verify the numerical results outside of the tool’s analytics. This can be especially risky when the numerical results are known to be noisy, as is the case with results produced by AI scorers.
As with interfaces, the form of a tool’s outputs can make it useful for different users in the red team, depending on their analytic needs. Comparing logs and statistics, there are two ends of the complexity spectrum, one favored for debugging and qualitative analyses and the other favored for leaderboards and quantitative comparisons. However, many other tool outputs exist beyond qualitative logs and numerical summaries. For example, some tools present a more holistic evaluation report, combining qualitative breakdowns of prompts and fine-grained numerical aggregates within the dataset. In particular, there is a large opportunity for the use of generative AI systems in red-teaming tool outputs, for qualitative and quantitative data processing and synthesis of novel findings from evaluation logs.
Guiding Questions for Choosing an AI Red-Teaming Tool
This survey illustrates the diversity among red-teaming tools, which are suited for different needs. With appropriate tools, testers can more quickly and thoroughly address their target threat model, but inappropriate tooling can hinder testers, obscure findings, and produce misleading results. To enable effective red-teaming, designers must choose software tools that align with their intended threat model and tester capabilities. With the variety of tools available, how can red-team designers pick the best one for their use case?
To help assess the fit between tools and red teams, here are some guiding questions to consider when creating or selecting a tool for a red-teaming exercise:
- Does the tool support access to the system you want to red-team?
- Is your target system a single LLM/AI model, or is it a multistep evaluation pipeline?
- Does the tool support the correct formats for your applied use case (e.g., text generation, image processing, tool use)?
- If the tool requires custom code to integrate with a new target system, does your team have the required skills to implement that?
- What downstream behavior do you want to evaluate with the red-teaming exercise?
- Does the tool provide access to the system in a way that mimics relevant threat actors?
- Is depth (i.e., specificity and optimization of testing) or breadth (i.e., coverage and volume of testing) more important to you?
- How important are interaction and adversarial testing to your threat model?
- What data are you planning to use?
- Will your testers be adapting inputs through the exercise, or can the behavior be tested through a fixed dataset?
- Do you have a custom set of known prompts/inputs to evaluate?
- Does the tool provide datasets that are relevant to your areas of concern (e.g., attack type, deployment context, format/modality)?
- Do you have any privacy/safety concerns about exposing sensitive data to the tool (e.g., if it is run through an external service)?
- How accessible is the tool to your testers?
- Does it require custom code, running on the command line, or does it have a graphical UI?
- Does the tool support your testers’ level of expertise in both the target evaluation domain and the red-teaming methodology?
- How much active engagement does the tool require from testers (vs. automation)?
- What information/metrics do you want to get out of the red-teaming exercise?
- What metrics and numerical analysis does the tool provide for you automatically?
- Is qualitative analysis important to your evaluation?
- How are query/evaluation logs stored, if at all? Are they provided in a useful format for your use case/technical appetite?
- How are you planning to ensure the validity and accuracy of your results? Does the tool provide any features to support this?
- How important is reproducibility to you? Does the tool enable repeated evaluations and save enough data for your reproduction needs?
- How well is the tool maintained?
- Is the tool released for free/open-source or as a paid service?
- Was the tool created for a one-off use case, or do the developers intend to continue updating it?
- Is there documentation (or direct support from the developers) that you can consult if issues arise from the tool?
Conclusion
There are now many tools available to facilitate red-teaming, such as adversarial attack benchmarks, prompt design tools, and even self-contained AI red-team testers. However, the tools used for red-teaming are designed with specific threat models in mind, which may not align with every red-teaming application. The design of a tool determines what target systems it can test, what threat behaviors it can mimic, what users it enables to do red-teaming, and what results it can relay. Benchmark-style tools offer convenience with more limited functionality, and evaluation harnesses enable flexibility but require more effort and expertise. Generative AI can accelerate testing and scoring but also introduces reliability risks. Interfaces and output formats trade off accessibility, control, completeness, and conciseness.
There is no universally appropriate red-teaming tool. However, red-team designers can use a series of questions to assess whether a tool’s threat model is well aligned with the evaluation threat model and tester capabilities. Well-aligned tools enable red teams to move faster, test more thoroughly, and draw stronger conclusions, but inappropriate tools can hinder teams and yield misleading results. By clearly identifying their own threat models and matching them to those implicit in various AI red-teaming tools, red teams can pick tools that fit their needs and empower their testers.
Acknowledgments
We thank Colin Shea-Blymyer, Drew Lohn, Jessica Ji, and Mina Narayanan for helpful comments and Chloe Moffett for editing feedback.
- For more, see: Ji, Jessica, “What Does AI Red-Teaming Actually Mean?” Center for Security and Emerging Technology, October 24, 2023, https://cset.georgetown.edu/article/what-does-ai-red-teaming-actually-mean/.
- The selection of tools and analysis in this survey are guided by the threat modeling view of AI, but many of these conclusions about the design implications of evaluation tools also apply to other AI testing methodologies.
- In the red-teaming tool catalog, evaluation harnesses are called “frameworks”, and benchmark-style tools are called “tools” and “toolkits.”